RAG架构与技术图谱
全面了解RAG系统的架构模式、技术栈、构建流程和关键技术
本页面收集了RAG(检索增强生成)领域最重要的架构图表和技术参考,帮助你快速掌握RAG系统的全貌。
RAG架构模式
8种主流RAG架构
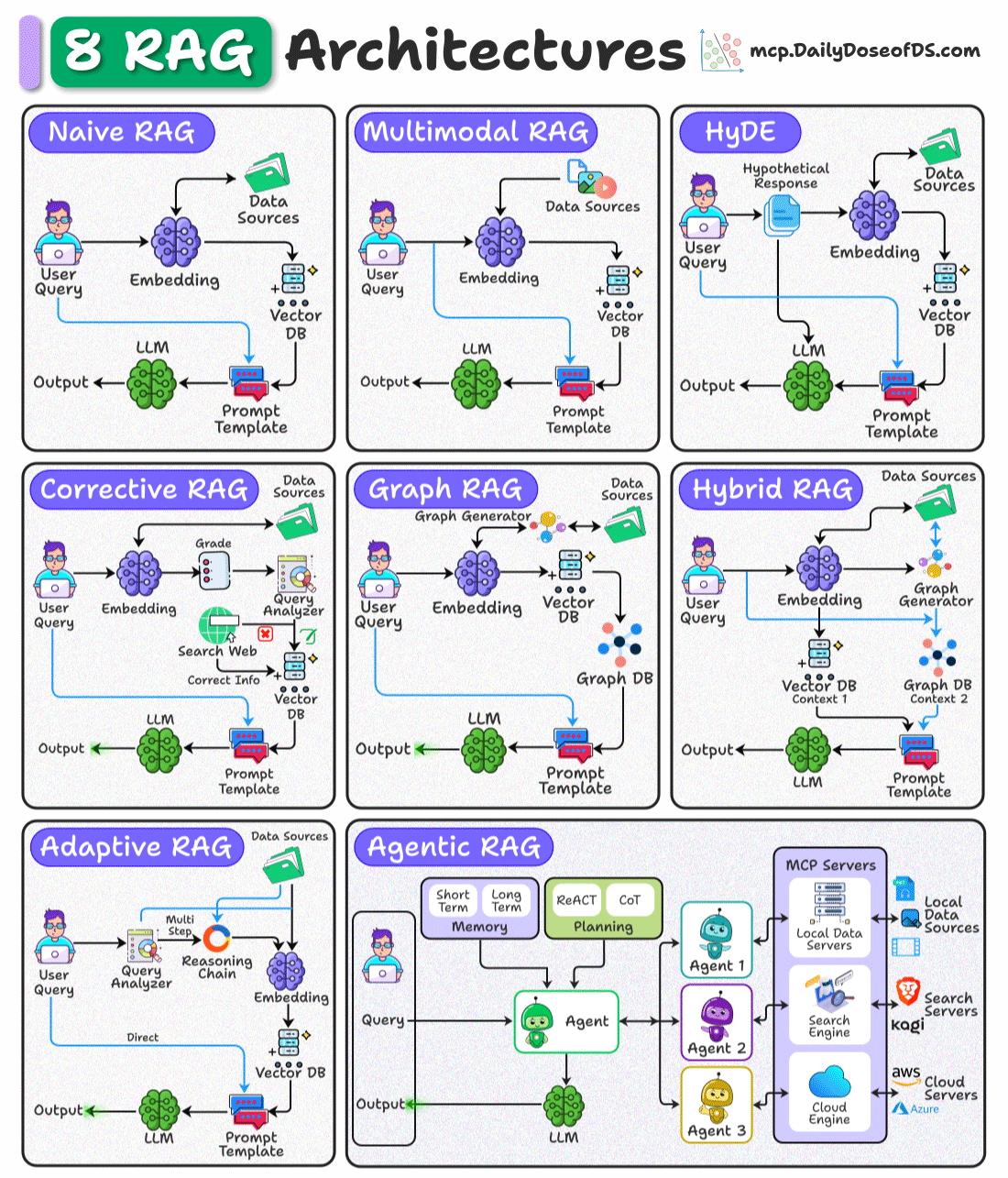
这张图展示了8种主流的RAG架构模式,每种都有其独特的应用场景:
- Naive RAG(基础RAG) - 最简单的RAG实现,用户查询 → 嵌入 → 检索 → 生成
- Multimodal RAG(多模态RAG) - 支持多种数据源(文本、图像等)的RAG系统
- HyDE(假设文档嵌入) - 先生成假设答案,再用假设答案检索相关文档
- Corrective RAG(纠正式RAG) - 通过评分和网络搜索来纠正检索结果
- Graph RAG(图RAG) - 利用知识图谱增强检索和推理能力
- Hybrid RAG(混合RAG) - 结合向量数据库和图数据库的优势
- Adaptive RAG(自适应RAG) - 根据查询复杂度动态选择检索策略
- Agentic RAG(代理式RAG) - 使用多个智能代理协同工作,支持复杂任务
RAG架构全景
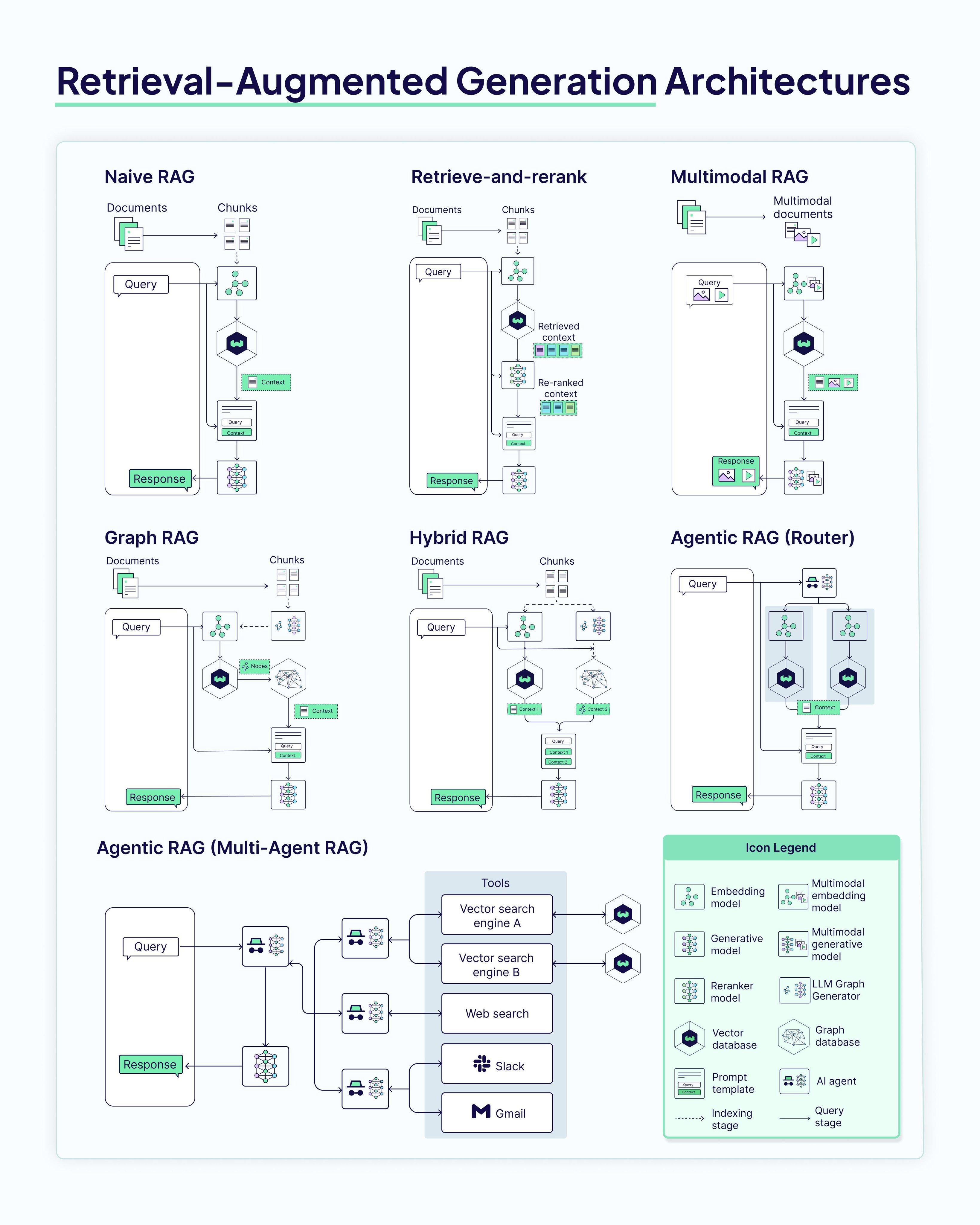
这张大图详细展示了各种RAG架构的内部工作流程和组件关系。
开源RAG技术栈
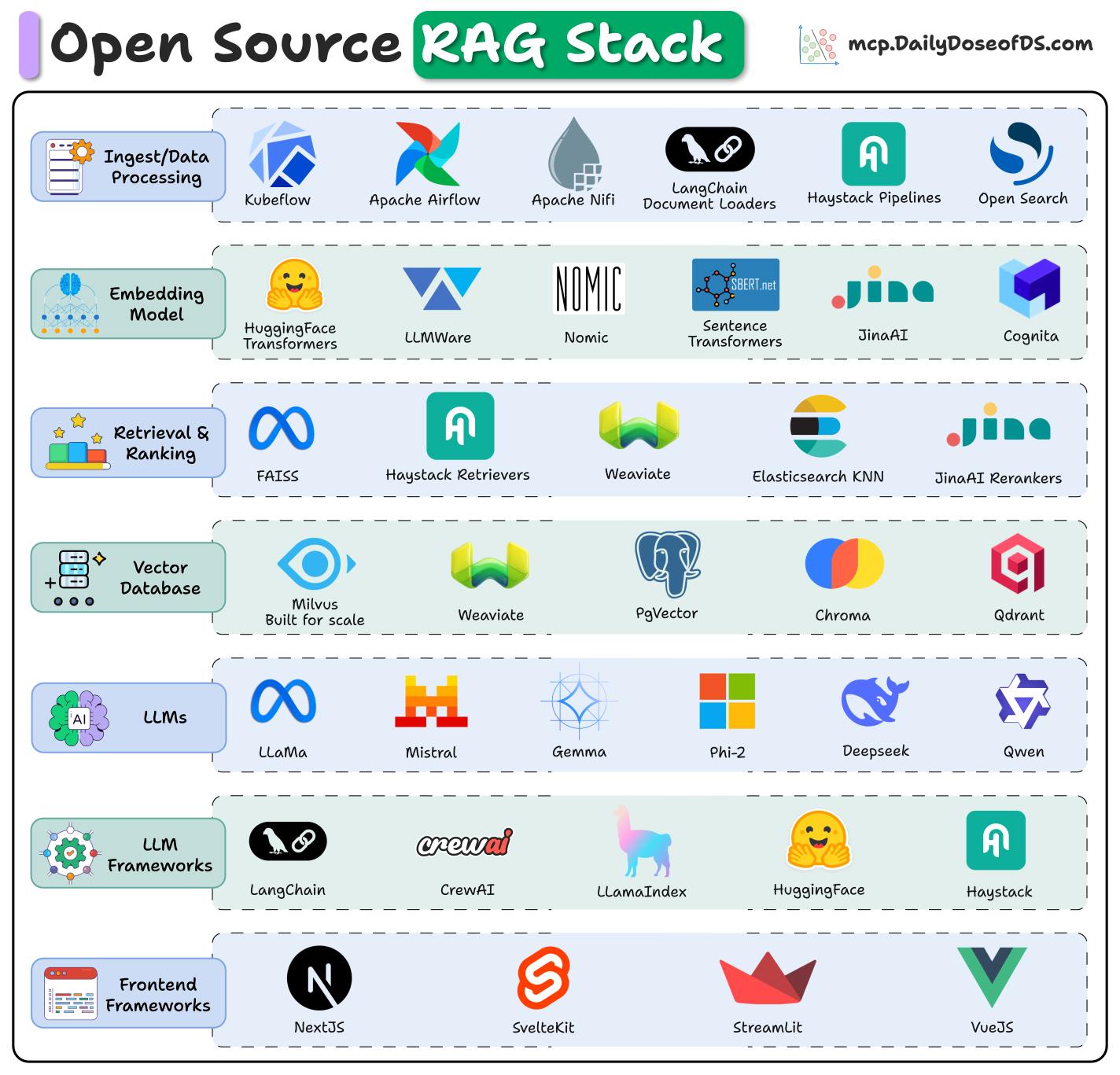
构建RAG系统需要多个技术层的支持,这张图展示了每一层的开源工具选择:
数据处理(Ingest/Data Processing)
- 数据源工具: Kubeflow, Apache Airflow, Apache Nifi
- 文档加载: LangChain Document Loaders, Haystack Pipelines, Open Search
嵌入模型(Embedding Model)
- 开源模型: HuggingFace Transformers, LLMWare, Nomic
- 句子编码: Sentence Transformers, JinaAI, Cognita
检索与排序(Retrieval & Ranking)
- 检索工具: FAISS, Haystack Retrievers, Weaviate
- 排序优化: Elasticsearch KNN, JinaAI Rerankers
向量数据库(Vector Database)
- 专用向量DB: Milvus, Weaviate, PgVector, Chroma, Qdrant
- 传统DB扩展: Elasticsearch, MongoDB, Open Search
- 知识图谱: Weaviate, Neo4j, Terminus DB, DiffBot
大语言模型(LLMs)
- 开源模型: LLaMA, Mistral, Gemma, Phi-2, Deepseek, Qwen
LLM框架
- 主流框架: LangChain, CrewAI, LLamaIndex, HuggingFace, Haystack
前端框架
- Web框架: NextJS, SvelteKit, StreamLit, VueJS
构建向量RAG的9个步骤
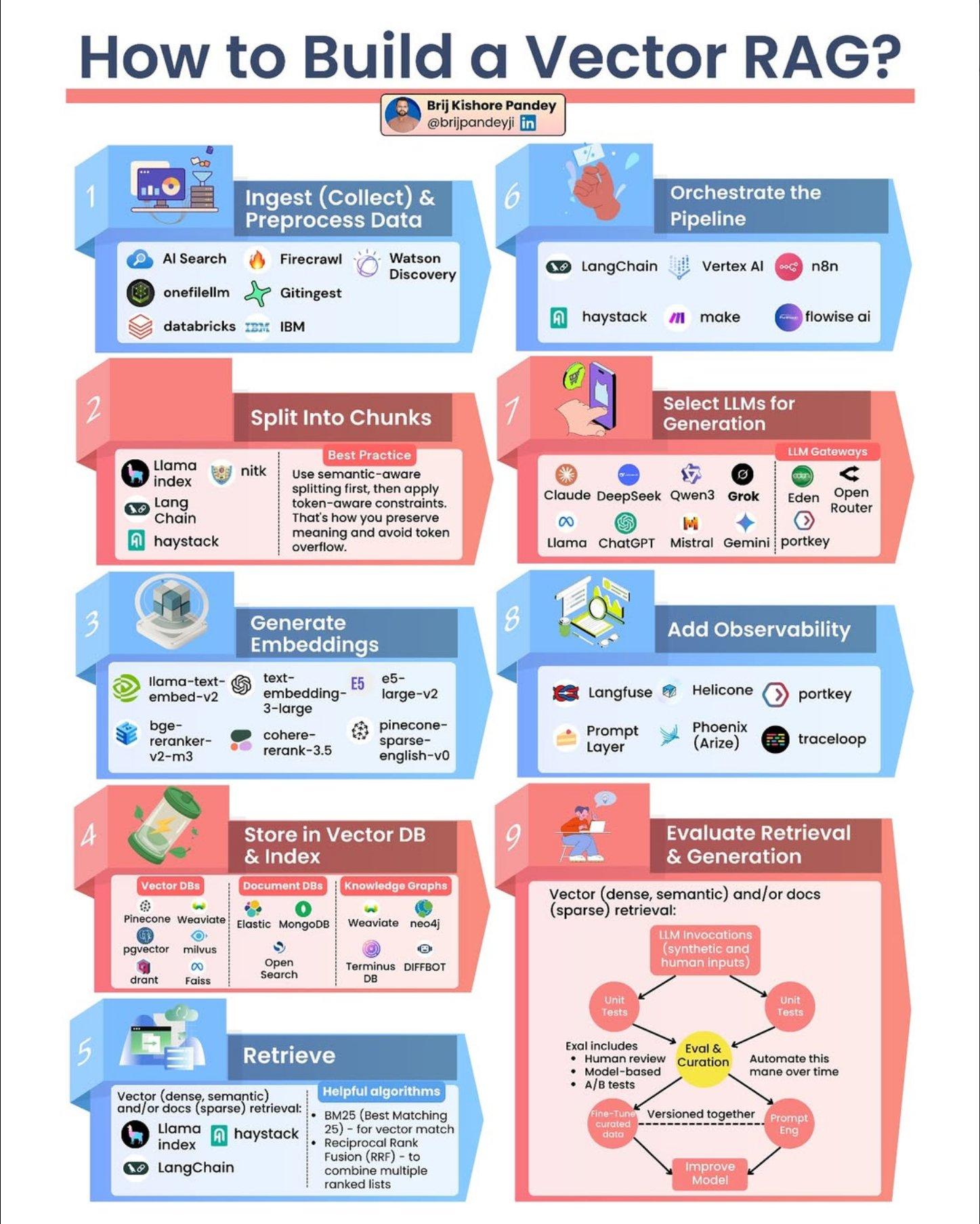
这张图详细说明了从零开始构建一个生产级向量RAG系统的完整流程:
1. 数据摄入与预处理(Ingest & Preprocess Data)
- 工具: AI Search, Firecrawl, Watson Discovery, onefilellm, Gitingest, databricks, IBM
2. 分块(Split into Chunks)
- 工具: Llama Index, NLTK, Long Chain, Haystack
- 最佳实践: 优先使用语义感知分块,然后应用token约束;保留文档结构,避免token溢出
3. 生成嵌入(Generate Embeddings)
- 模型: llama-text-embed-v2, text-embedding-3-large, bge-reranker-v2-m3, cohere-rerank-3.5, e5-large-v2, pinecone-sparse-english-v0
4. 存储到向量数据库(Store in Vector DB & Index)
- 向量数据库: Pinecone, Weaviate, Elastic, pgvector, milvus, qdrant, faiss
- 文档数据库: MongoDB, Elastic, Open Search
- 知识图谱: Weaviate, neo4j, Terminus DB, DiffBot
5. 检索(Retrieve)
- 检索方式: 向量检索(密集/语义)或文档检索(稀疏)
- 工具: Llama Index, Haystack, LangChain
- 算法: BM25(Best Matching 25)向量匹配,倒数排序融合(RRF)合并多个排序列表
6. 编排流程(Orchestrate the Pipeline)
- 编排工具: LangChain, Vertex AI, n8n, haystack, make, flowise.ai
7. 选择生成模型(Select LLMs for Generation)
- LLM网关: Claude, Deepseek, Qwen3, Grok, Eden, Open Router
- 开源模型: Llama, ChatGPT, Mistral, Gemini, portkey
8. 添加可观测性(Add Observability)
- 监控工具: Langfuse, Helicone, portkey, Prompt Layer, Phoenix (Arize), traceloop
9. 评估检索与生成(Evaluate Retrieval & Generation)
- 评估方法: 向量(密集/语义)和/或文档(稀疏)检索
- 评估指标: LLM调用、合成和人工输入
- 评估内容:
- 单元测试
- 人工审查
- 基于模型的A/B测试
- 持续改进:
- 评估与管理
- 版本化管理
- 随时间自动改进模型
分块技术详解
分块(Chunking)是RAG系统中至关重要的预处理步骤,直接影响检索质量。合理的分块策略能显著提升RAG系统的检索准确率和生成质量。
分块策略全景

这张图全面展示了分块的两大类方法和多种高级技术:
Pre vs Post Chunking(前置分块 vs 后置分块)
Pre-Chunking(前置分块 - Option #1)
- 流程: 文档 → 分块 → 嵌入模型 → 向量数据库
- 特点: 将文档分割成较小的块(如100个token),然后为每个块单独生成嵌入
- 优势: 实现简单,处理速度快
- 检索方式:
- 通过语义相似度检索
- 增强上下文后输入提示模板
- 由大语言模型生成回答
Post-Chunking(后置分块 - Option #2)
- 流程: 文档 → 嵌入模型 → 分块 → 向量数据库
- 特点: 先将整个文档嵌入,然后在LLM上下文窗口中存储分块文档
- 优势: 保留文档的全局上下文信息,避免语义碎片化
- 检索方式:
- 通过语义相似度检索整个文档
- 从检索到的文档中提取相关块
- 增强上下文后由大语言模型生成
Simple Chunking Techniques(简单分块技术)
1. Fixed-Size Chunking(固定大小分块)
- 将文本分割成固定大小的块,使用重叠(overlap)来保持上下文连续性
- 示例:"Photosynthesis is one of nature's most vital processes" 被分成3个重叠的块
2. Recursive Chunking(递归分块)
- 定义分隔符层次结构(如段落 → 句子)
- 使用最高级别分隔符分割文本
- 如果块太大,使用下一级分隔符递归分割
- 重复此过程直至达到期望大小
3. Document Based Chunking(基于文档的分块)
- 识别自然的文档边界(如标题、子标题)
- 根据这些边界创建块
- 根据需要进一步分割过大的块
- 存储带有特殊标记的块以保留结构
Advanced Chunking Techniques(高级分块技术)
1. Semantic Chunking(语义分块)
- 对文本列表执行段落或句子的向量化
- 计算向量化句子之间的余弦距离
- 基于余弦距离计算句子组
- 合并和重组文本为块
2. Agentic Chunking(代理分块)
- 使用AI代理智能决定分块策略
- 根据文档类型和内容特征动态调整
- 可以处理复杂的文档结构
3. Late Chunking(延迟分块)
- 先对整个文档池化生成嵌入
- 保留上下文信息
- 将嵌入分块
- 嵌入整个文档,避免语义碎片化
4. LLM-Based Chunking(基于LLM的分块)
- 使用大语言模型分析文本
- 生成语义独立的命题(propositions)
- 示例:"Alex visited the library. He loves reading." → "Alex visited the library." + "Alex loves reading."
5. Hierarchical Chunking(层次分块)
- 创建文档的层次结构
- 父块包含多个子块
- 支持多级检索和上下文扩展
详细技术对比

下面是6种主要分块技术的详细对比:
1. Fixed-Size Chunking(固定大小分块)
- 特点: 将文本分割成固定大小的块,不考虑自然断点或内容结构
- 优点: 简单且成本效益高
- 缺点: 缺乏上下文感知
- 改进: 可以使用重叠块(overlapping chunks),让相邻块共享部分内容
2. Recursive Chunking(递归分块)
- 特点: 使用主分隔符(如段落)初始分割,如果块太大,则递归应用次级分隔符(如句子)
- 优点: 尊重文档结构,灵活适用于各种场景
3. Document-Based Chunking(基于文档的分块)
- 特点: 基于文档的自然分割(如标题或章节)创建块
- 适用场景: 对HTML、Markdown或代码文件等结构化数据非常有效
- 局限: 对缺乏明确结构元素的数据不太适用
4. Semantic Chunking(语义分块)
- 特点: 将文本分割成有意义的单元(如句子或段落),然后向量化这些单元
- 原理: 基于嵌入之间的余弦距离合并块,当检测到显著的上下文变化时形成新块
- 优点: 保持语义完整性
5. LLM-Based Chunking(基于LLM的分块)
- 特点: 使用大语言模型处理文本并生成语义隔离的句子或命题
- 优点: 高度准确,可以独立理解每个块
- 缺点: 计算成本最高
6. Late Chunking(延迟分块)
- 特点: 颠覆传统流程,先嵌入整个文档,再分块
- 原理:
- 传统方法:先分块再单独嵌入每个块
- 延迟分块:使用长上下文模型嵌入整个文档,然后将token级嵌入分割并池化为多个块表示
- 优点: 更好地保留大文档的上下文信息
- 可视化: 图中展示了嵌入模型处理整个文本后的token级嵌入分布
选择建议
架构选择
- 简单场景: 从Naive RAG开始,快速验证想法
- 多模态需求: 选择Multimodal RAG
- 高准确度要求: 考虑Corrective RAG或Graph RAG
- 复杂任务: 使用Agentic RAG或Adaptive RAG
分块策略选择
- 结构化文档: Document-Based Chunking
- 通用场景: Semantic Chunking或Recursive Chunking
- 高质量要求: LLM-Based Chunking
- 长文档: Late Chunking
- 快速原型: Fixed-Size Chunking
技术栈选择
根据团队技能、项目规模和预算,从上述开源技术栈中选择合适的工具组合。建议:
- 初学者: LangChain + OpenAI + Pinecone
- Python生态: LlamaIndex + HuggingFace + Weaviate
- 企业级: Haystack + Custom Models + Elasticsearch