[实战] Qwen3嵌入与重排序
Complete tutorial on building a RAG system using Qwen3-Embedding-0.6B and Qwen3-Reranker-0.6B with Milvus. 完整教程,介绍如何使用 Milvus 构建基于 Qwen3-Embedding-0.6B 和 Qwen3-Reranker-0.6B 的 RAG 系统。
Hands-on RAG with Qwen3 Embedding and Reranking Models using Milvus
使用 Milvus 的 Qwen3 嵌入和重排序模型进行 RAG 实践
If you've been keeping an eye on the embedding model space, you've probably noticed Alibaba just dropped their Qwen3 Embedding series. They released both embedding and reranking models in three sizes each (0.6B, 4B, 8B), all built on the Qwen3 foundation models and designed specifically for retrieval tasks.
The Qwen3 series has a few features I found interesting:
- Multilingual embeddings - they claim a unified semantic space across 100+ languages
- Instruction prompting - you can pass custom instructions to modify embedding behavior
- Variable dimensions - supports different embedding sizes via Matryoshka Representation Learning
- 32K context length - can process longer input sequences
- Standard dual/cross-encoder setup - embedding model uses dual-encoder, reranker uses cross-encoder
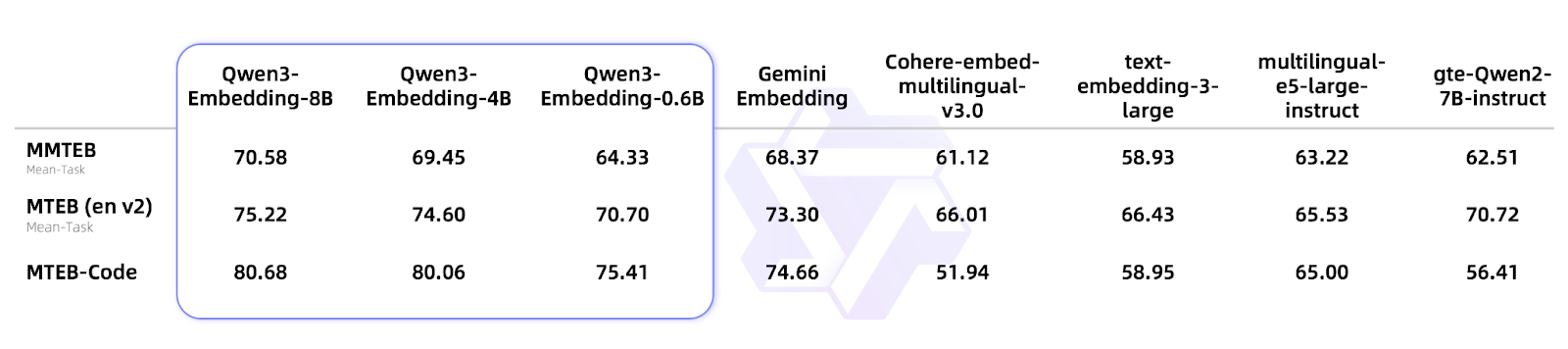
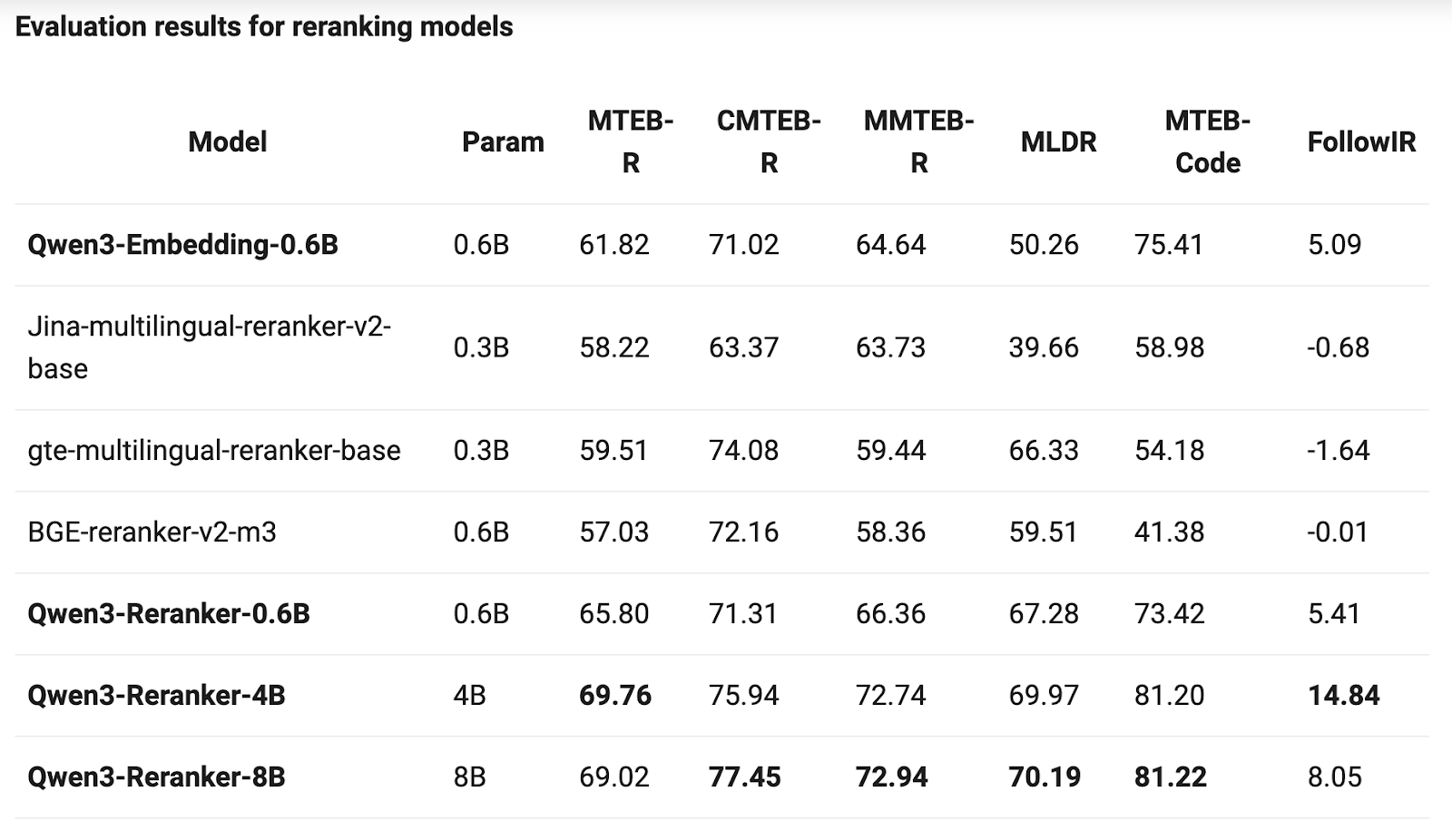
Looking at the benchmarks, Qwen3-Embedding-8B achieved a score of 70.58 on the MTEB multilingual leaderboard, surpassing BGE, E5, and even Google Gemini. The Qwen3-Reranker-8B hit 69.02 on multilingual ranking tasks. These aren't just "pretty good among open-source models" - they're comprehensively matching or even surpassing mainstream commercial APIs. In RAG retrieval, cross-language search, and code search systems, especially in Chinese contexts, these models already have production-ready capabilities.
As someone who's likely dealt with the usual suspects (OpenAI's embeddings, BGE, E5), you might be wondering if these are worth your time. Spoiler: they are.
This tutorial walks through building a complete RAG system using Qwen3-Embedding-0.6B and Qwen3-Reranker-0.6B with Milvus. We'll implement a two-stage retrieval pipeline:
- Dense retrieval with Qwen3 embeddings for fast candidate selection
- Reranking with Qwen3 cross-encoder for precision refinement
- Generation with OpenAI's GPT-4 for final responses
By the end, you'll have a working system that handles multilingual queries, uses instruction prompting for domain tuning, and balances speed with accuracy through intelligent reranking.
Dependencies
Let's start with the dependencies. Note the minimum version requirements - they're important for compatibility:
pip install --upgrade pymilvus openai requests tqdm sentence-transformers transformersRequires transformers>=4.51.0 and sentence-transformers>=2.7.0
For this tutorial, we'll use OpenAI as our generation model. Set up your API key:
import os
os.environ["OPENAI_API_KEY"] = "sk-**********"Data Preparation
We'll use Milvus documentation as our knowledge base - it's a good mix of technical content that tests both retrieval and generation quality. Download and extract the documentation:
wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
unzip -q milvus_docs_2.4.x_en.zip -d milvus_docsLoad and chunk the markdown files. We're using a simple header-based splitting strategy here - for production systems, consider more sophisticated chunking approaches:
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")Model Initialization
Now let's initialize our models. We're using the lightweight 0.6B versions, which offer a good balance of performance and resource requirements:
from openai import OpenAI
from sentence_transformers import SentenceTransformer
import torch
from transformers import AutoModel, AutoTokenizer, AutoModelForCausalLM
# Initialize OpenAI client for LLM generation
openai_client = OpenAI()
# Load Qwen3-Embedding-0.6B model for text embeddings
embedding_model = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
# Load Qwen3-Reranker-0.6B model for reranking
reranker_tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-Reranker-0.6B", padding_side='left')
reranker_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-Reranker-0.6B").eval()
# Reranker configuration
token_false_id = reranker_tokenizer.convert_tokens_to_ids("no")
token_true_id = reranker_tokenizer.convert_tokens_to_ids("yes")
max_reranker_length = 8192Milvus Setup
Initialize Milvus and create a collection for our vectors:
from pymilvus import (
connections,
utility,
FieldSchema, CollectionSchema, DataType,
Collection,
)
# Connect to Milvus
connections.connect("default", host="localhost", port="19530")
# Define schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1792) # Qwen3-Embedding dimension
]
schema = CollectionSchema(fields, "Qwen3 RAG tutorial")
# Create collection
collection_name = "qwen3_rag_tutorial"
collection = Collection(collection_name, schema)
# Create index
index_params = {
"index_type": "HNSW",
"metric_type": "IP", # Inner product for Qwen3 embeddings
"params": {"M": 8, "efConstruction": 64}
}
collection.create_index("embedding", index_params)Data Ingestion
Process and insert our text data into Milvus:
# Process text chunks
texts = []
embeddings = []
for text in text_lines:
if len(text.strip()) > 0:
# Generate embedding
embedding = embedding_model.encode(text)
texts.append(text)
embeddings.append(embedding.tolist())
# Insert data
batch_size = 100
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
batch_embeddings = embeddings[i:i+batch_size]
collection.insert([batch_texts, batch_embeddings])
# Flush and load
collection.flush()
collection.load()Retrieval Pipeline
Implement the two-stage retrieval pipeline:
def retrieve_and_rerank(query, top_k=10, rerank_top_k=3):
# Stage 1: Dense retrieval
query_embedding = embedding_model.encode(query).tolist()
search_params = {
"metric_type": "IP",
"params": {"ef": 64}
}
results = collection.search(
data=[query_embedding],
anns_field="embedding",
param=search_params,
limit=top_k,
output_fields=["text"]
)
# Extract retrieved texts
retrieved_texts = [hit.entity.get("text") for hit in results[0]]
# Stage 2: Reranking
reranked_scores = []
for text in retrieved_texts:
# Prepare input for reranker
input_text = f"{query} => {text}"
inputs = reranker_tokenizer(
input_text,
return_tensors="pt",
truncation=True,
max_length=max_reranker_length
)
# Get reranker score
with torch.no_grad():
outputs = reranker_model(**inputs)
logits = outputs.logits[0, -1, [token_false_id, token_true_id]]
scores = torch.softmax(logits, dim=0)
reranked_scores.append(scores[1].item()) # Probability of "yes"
# Sort by reranker scores
reranked_indices = sorted(range(len(reranked_scores)), key=lambda i: reranked_scores[i], reverse=True)
reranked_texts = [retrieved_texts[i] for i in reranked_indices[:rerank_top_k]]
reranked_scores_sorted = [reranked_scores[i] for i in reranked_indices[:rerank_top_k]]
return reranked_texts, reranked_scores_sorted
# Example usage
query = "How does Milvus handle vector data types and precision?"
contexts, scores = retrieve_and_rerank(query)
print("Retrieved contexts:")
for i, (context, score) in enumerate(zip(contexts, scores)):
print(f"{i+1}. Score: {score:.4f}")
print(f" Context: {context[:200]}...")
print()Generation
Finally, use the retrieved context to generate a response:
SYSTEM_PROMPT = """You are a helpful assistant specialized in Milvus vector database.
Answer questions based on the provided context. If the context doesn't contain relevant information,
say so rather than making up information."""
USER_PROMPT = """
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
# Generate response
context_text = "\n\n".join(contexts)
formatted_prompt = USER_PROMPT.format(context=context_text, question=query)
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": formatted_prompt},
],
)
print(response.choices[0].message.content)Expected output:
In Milvus, data is stored in two main forms: inserted data and metadata. Inserted data, which includes vector data, scalar data, and collection-specific schema, is stored in persistent storage as incremental logs. Milvus supports multiple object storage backends for this purpose, including MinIO, AWS S3, Google Cloud Storage, Azure Blob Storage, Alibaba Cloud OSS, and Tencent Cloud Object Storage. Metadata for Milvus is generated by its various modules and stored in etcd.Conclusion
This tutorial demonstrated a complete RAG implementation using Qwen3's embedding and reranking models. The key takeaways:
- Two-stage retrieval (dense + reranking) consistently improves accuracy over embedding-only approaches
- Instruction prompting allows domain-specific tuning without retraining
- Multilingual capabilities work naturally without additional complexity
- Local deployment is feasible with the 0.6B models
The Qwen3 series offers solid performance in a lightweight, open-source package. While not revolutionary, they provide incremental improvements and useful features like instruction prompting that can make a real difference in production systems.
Test these models against your specific data and use cases - what works best always depends on your content, query patterns, and performance requirements.
[实战] Milvus BM25混合检索
了解如何利用 Milvus 2.5 版本实现快速的全文检索、关键词匹配,以及混合检索(Hybrid Search),并将其应用于RAG系统。
[实战] Elysia智能体RAG应用
Learn how to build end-to-end agentic RAG applications using Weaviate's open-source framework Elysia, enabling dynamic decision-making, data visualization, and transparent AI interaction experiences. / 了解如何使用 Weaviate 的开源框架 Elysia 构建端到端的智能体 RAG 应用,实现动态决策、数据可视化和透明的 AI 交互体验。