[实战] Milvus BM25混合检索
了解如何利用 Milvus 2.5 版本实现快速的全文检索、关键词匹配,以及混合检索(Hybrid Search),并将其应用于RAG系统。
通过Milvus的BM25算法进行全文检索并将混合检索应用于RAG系统
本文介绍如何利用 Milvus 2.5 版本实现快速的全文检索、关键词匹配,以及混合检索(Hybrid Search)。通过增强向量相似性检索和数据分析的灵活性,提升了检索精度,并演示了在 RAG 应用的 Retrieve 阶段如何使用混合检索提供更精确的上下文以生成回答。
Milvus 2.5 集成了高性能搜索引擎库 Tantivy ,并内置 Sparse-BM25 算法,首次实现了原生全文检索功能。这一能力与现有的语义搜索功能完美互补,为用户提供更强大的检索体验。
内置分词器:无需额外预处理,通过内置分词器(Analyzer)与稀疏向量提取能力,Milvus 可直接接受文本输入,自动完成分词、停用词过滤与稀疏向量提取。
已创建内核版本为 2.5 的 Milvus 实例。具体操作,请参见快速创建 Milvus 实例。
步骤一:连接 Milvus 并准备数据
在开始之前,请确保您已完成以下准备工作:
- 已创建内核版本为 2.5 的 Milvus 实例。具体操作,请参见快速创建 Milvus 实例。
- 已获取 Milvus 实例的内网地址或公网地址。
- 已获取登录 Milvus 实例的用户名和密码。
- 已安装 Python 3.8 或以上版本。
- 已安装 Milvus Python SDK。具体操作,请参见安装 Milvus Python SDK。
from pymilvus import (
MilvusClient,
DataType,
AnnSearchRequest,
RRFRanker
)
from langchain_community.embeddings import DashScopeEmbeddings
import dashscope
# 替换为您的 DashScope API-KEY
dashscope_api_key = "<YOUR_DASHSCOPE_API_KEY>"
# 初始化 Embedding 模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 使用text-embedding-v2模型。
dashscope_api_key=dashscope_api_key
)
# 替换为您的 Milvus 实例信息
milvus_url = "<YOUR_MILVUS_URL>"
user_name = "<YOUR_USERNAME>"
password = "<YOUR_PASSWORD>"
# 创建 Milvus Client
client = MilvusClient(
uri="http://" + milvus_url + ":19530",
token=user_name + ":" + password
)
# 定义 Collection 名称
collection_name = "milvus_bm25_hybrid"
# 定义文本内容
text_contents = [
"Milvus is a highly scalable vector database designed for AI applications. It offers high performance and hybrid search capabilities.",
"Milvus supports multiple indexing algorithms, including IVF, HNSW, and DiskANN, to ensure efficient similarity search.",
"Milvus is compatible with various ecosystems, including LangChain, LlamaIndex, and ChatGLM.",
"Milvus provides a unified platform for data management, including data ingestion, processing, and querying.",
"Milvus offers enterprise-grade security features, including authentication, authorization, and encryption.",
"Milvus is optimized for cloud environments and supports Kubernetes deployment for easy scaling.",
"Milvus has a comprehensive set of APIs and SDKs for various programming languages, including Python, Java, and Go.",
"Milvus supports both sparse and dense vector search, enabling hybrid search capabilities.",
"Milvus provides a web-based management interface for easy monitoring and administration.",
"Milvus is an open-source project with a vibrant community and extensive documentation."
]
# 生成向量
vectors = embeddings.embed_documents(text_contents)
dense_dim = len(vectors[0])
# 定义 Schema
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
)
schema.add_field(
field_name="dense",
datatype=DataType.FLOAT_VECTOR,
dim=dense_dim
)
# 定义索引参数
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense",
index_type="HNSW",
metric_type="IP",
params={"M": 8, "efConstruction": 96}
)
# 定义分词器参数
analyzer_params = {
"type": "english" # 指定分词器类型为英文
}
# 添加文本字段到 Schema,并启用分词器
schema.add_field(
field_name="text", # 字段名称
datatype=DataType.VARCHAR, # 数据类型:字符串(VARCHAR)
max_length=65535, # 最大长度:65535 字符
enable_analyzer=True, # 启用分词器
analyzer_params=analyzer_params # 分词器参数
)
index_params.add_index(
field_name="text",
index_name="text_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={"drop_ratio_build": 0.2}
)
# 创建 collection
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
data = [
{"id": idx, "dense": vectors[idx], "text": doc}
for idx, doc in enumerate(text_contents)
]
# 插入数据
res = client.insert(
collection_name=collection_name,
data=data
)
print("生成 " + str(len(vectors)) + " 个向量,维度:" + str(len(vectors[0])))本文示例涉及以下参数,请您根据实际环境替换。
| 参数 | 说明 |
|---|---|
dashscope_api_key | 阿里云百炼的 API-KEY。 |
milvus_url | Milvus 实例的内网地址或公网地址。您可以在 Milvus 实例的实例详情页面查看。 |
| * 如果使用内网地址,请确保客户端与 Milvus 实例在同一 VPC 内。 | |
| * 如果使用公网地址,请开启公网,并确保安全组规则允许相应的端口通信,详情请参见网络访问类型。 | |
user_name | 创建 Milvus 实例时,您自定义的用户名和密码。 |
password | |
collection_name | Collection 的名称。您可以自定义。本文示例均以 milvus_bm25_hybrid 为例。 |
dense_dim | 稠密向量维度。鉴于 text-embedding-v2 模型生成的向量维度为 1536 维,因此将 dense_dim 设置为 1536。 |
该示例使用了 Milvus 2.5 最新的能力,通过创建 bm25_function 对象,Milvus 就可以自动地将文本列转换为稀疏向量。
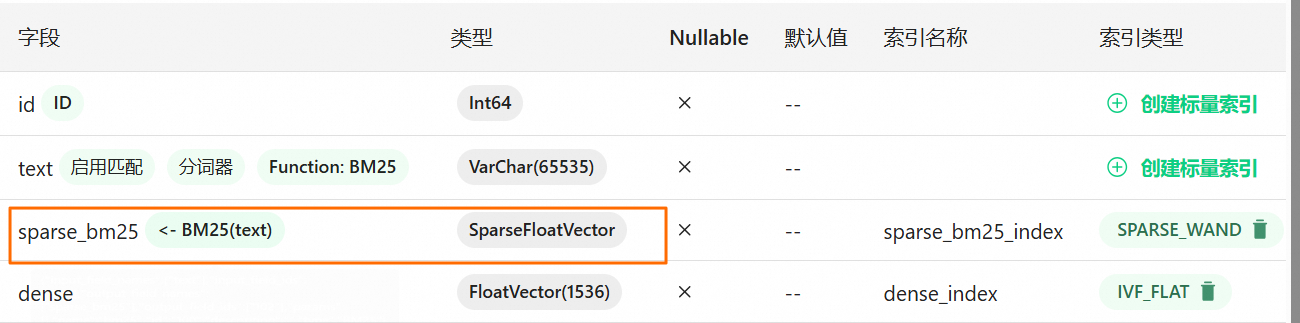
同样,在处理中文文档时,Milvus 2.5 版本也支持指定相应的中文分析器。
重要
在 Schema 中完成 Analyzer 的设置后,该设置将对该 Collections 永久生效。如需设置新的 Analyzer,则必须重新创建 Collection。
步骤二:混合检索
结合向量搜索和全文检索,通过 RRF(Reciprocal Rank Fusion) 算法融合向量和文本检索结果,重新优化排序和权重分配,提升数据召回率和精确性。
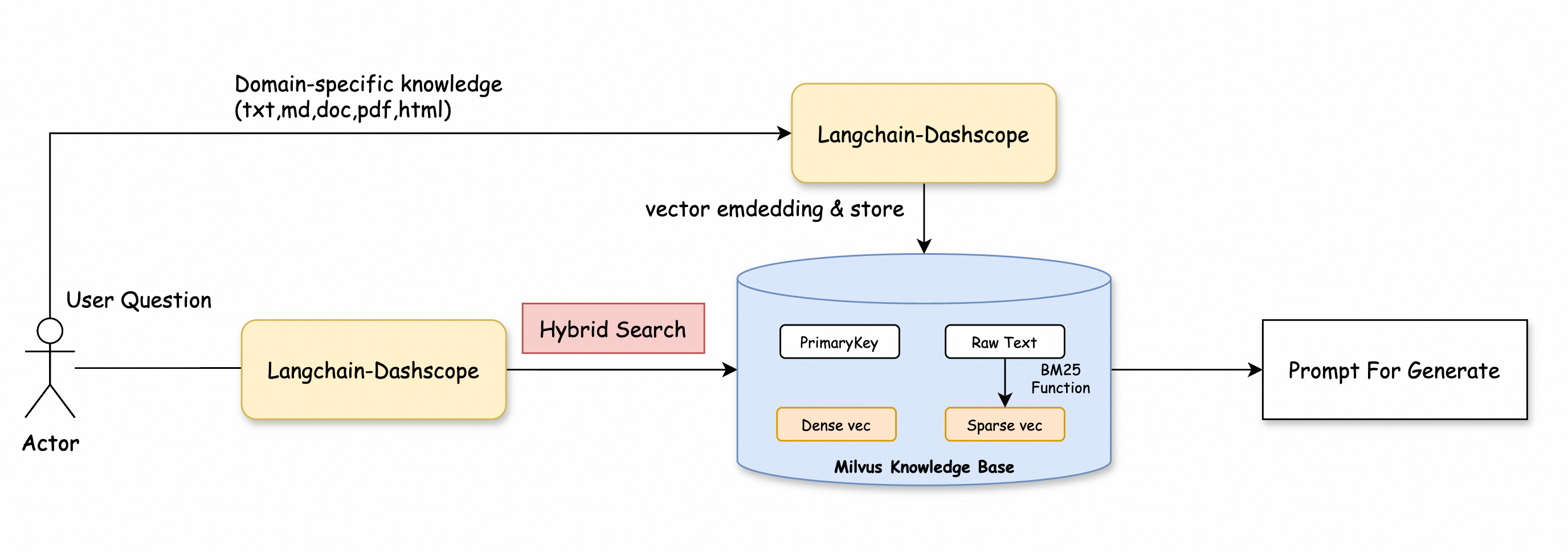
代码示例如下所示。
from pymilvus import MilvusClient
from pymilvus import AnnSearchRequest, RRFRanker
from langchain_community.embeddings import DashScopeEmbeddings
from dashscope import Generation
# 创建Milvus Client。
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530", # Milvus实例的公网地址。
token="<yourUsername>:<yourPassword>", # 登录Milvus实例的用户名和密码。
db_name="default" # 待连接的数据库名称,本文示例为默认的default。
)
collection_name = "milvus_bm25_hybrid"
# 替换为您的 DashScope API-KEY
dashscope_api_key = "<YOUR_DASHSCOPE_API_KEY>"
# 初始化 Embedding 模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 使用text-embedding-v2模型。
dashscope_api_key=dashscope_api_key
)
# Define the query
query = "Why does Milvus run so scalable?"
# Embed the query and generate the corresponding vector representation
query_embeddings = embeddings.embed_documents([query])
# Set the top K result count
top_k = 5 # Get the top 5 docs related to the query
# Define the parameters for the dense vector search
search_params_dense = {
"metric_type": "IP",
"params": {"nprobe": 2}
}
# Create a dense vector search request
request_dense = AnnSearchRequest([query_embeddings[0]], "dense", search_params_dense, limit=top_k)
# Define the parameters for the BM25 text search
search_params_bm25 = {
"metric_type": "BM25"
}
# Create a BM25 text search request
request_bm25 = AnnSearchRequest([query], "text", search_params_bm25, limit=top_k)
# Combine the two requests
reqs = [request_dense, request_bm25]
# Initialize the RRF ranking algorithm
ranker = RRFRanker(100)
# Perform the hybrid search
hybrid_search_res = client.hybrid_search(
collection_name=collection_name,
reqs=reqs,
ranker=ranker,
limit=top_k,
output_fields=["text"]
)
# Extract the context from hybrid search results
context = []
print("Top K Results:")
for hits in hybrid_search_res: # Use the correct variable here
for hit in hits:
context.append(hit['entity']['text']) # Extract text content to the context list
print(hit['entity']['text']) # Output each retrieved document
# Define a function to get an answer based on the query and context
def getAnswer(query, context):
# Build the prompt using the query and context
prompt_text = "Please answer my question based on the content within:\n\n"
prompt_text += str(context) + "\n\n"
prompt_text += "My question is: " + query
# Call the generation module to get an answer
rsp = Generation.call(model='qwen-turbo', prompt=prompt_text)
return rsp.output.text
# Get the answer
answer = getAnswer(query, context)
print(answer)
# Expected output excerpt
Milvus is highly scalable due to its cloud-native and highly decoupled system architecture. This architecture allows the system to continuously expand as data grows. Additionally, Milvus supports three deployment modes that cover a wide range of application scenarios.