高级RAG - 提升RAG性能
Ultimate guide to optimise RAG pipeline from zero to advance - Solving the core challenges of Retrieval-Augmented Generation
高级RAG - 提升RAG性能
Ultimate guide to optimise RAG pipeline from zero to advance- Solving the core challenges of Retrieval-Augmented Generation 优化RAG管道从零到高级的终极指南 - 解决检索增强生成的核心挑战
10 min read 10分钟阅读
Feb 26, 2024 2024年2月26日
In my last blog, I covered RAG extensively and how it's implemented with LlamaIndex. However, RAG often encounters numerous challenges when answering questions. In this blog, I'll address these challenges and, more importantly we will delve into solutions to improve RAG performance, making it production-ready. 在我上一篇博客中,我广泛地介绍了RAG以及如何用LlamaIndex实现它。然而,RAG在回答问题时经常遇到许多挑战。在这篇博客中,我将解决这些挑战,更重要的是,我们将深入探讨提升RAG性能的解决方案,使其达到生产就绪状态。
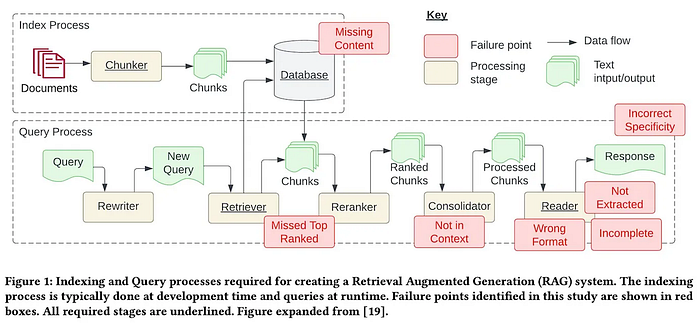
Image source: Seven Failure Points When Engineering a Retrieval Augmented Generation System 图片来源:构建检索增强生成系统的七个故障点
I'll discuss various optimization techniques sourced from different research papers. The majority of these techniques will be based on a research paper I particularly enjoyed, titled "Retrieval-Augmented Generation for Large Language Models: A Survey." This paper encompasses most recent optimization methods. 我将讨论来自不同研究论文的各种优化技术。这些技术大部分将基于我特别喜欢的一篇研究论文,题为"面向大语言模型的检索增强生成:一项调查"。这篇论文涵盖了最新的优化方法。
Breakdown of RAG workflow RAG工作流程分解
First, we will breakdown RAG workflow into three parts to enhance our understanding of RAG and optimise each of these parts to improve overall performance: 首先,我们将把RAG工作流程分解为三个部分,以增强我们对RAG的理解,并优化每个部分以提高整体性能:
Pre-Retrieval 预检索
In the pre-retrieval step, the new data outside of the LLM's original training dataset, also called external data has be prepared and split into chunks and then index the chunk data using embedding models that converts data into numerical representations and stores it in a vector database. This process creates a knowledge library that the LLM can understand. 在预检索步骤中,LLM原始训练数据集之外的新数据,也称为_外部数据_,需要被准备并分割成块,然后使用_嵌入模型_对块数据进行索引,将数据转换为数值表示并存储在向量数据库中。这个过程创建了LLM可以理解的知识库。
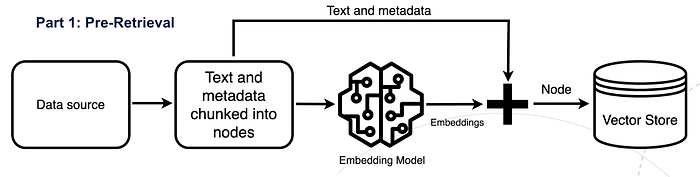
Pre-Retrieval in RAG RAG中的预检索
Retrieval 检索
In the most important retrieval step, the user query is converted to a vector representation called embedding and finds a relavent chunks using cosine similarity from the vector database. And this tried to find highly-relevant document chunks from vector store. 在最重要的检索步骤中,用户查询被转换为称为嵌入的向量表示,并使用余弦相似性从向量数据库中找到相关的块。这试图从向量存储中找到高度相关的文档块。
Post-Retrieval 后检索
Next, the RAG model augments the user input (or prompts) by adding the relevant retrieved data in context (query + context). This step uses prompt engineering techniques to communicate effectively with the LLM. The augmented prompt allows the large language models to generate an accurate answer to user queries using given context. 接下来,RAG模型通过在上下文中添加相关的检索数据来增强用户输入(或提示)(查询+上下文)。此步骤使用提示工程技术与LLM进行有效通信。增强的提示允许大语言模型使用给定上下文为用户查询生成准确答案。
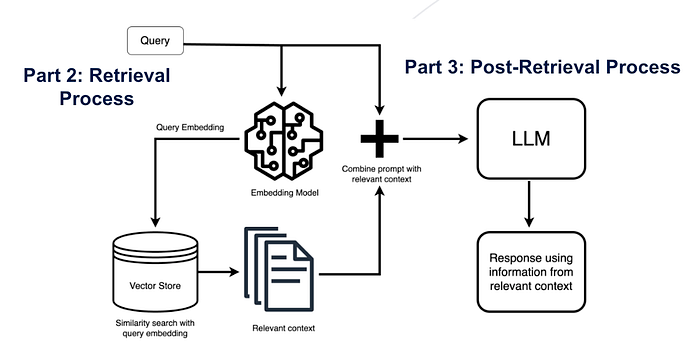
Retrieval and Post-Retrieval in RAG RAG中的检索和后检索
Goal 目标
We aim to enhance each component of the RAG workflow by applying various techniques to different parts. 我们的目标是通过在不同部分应用各种技术来增强RAG工作流程的每个组件。
Pre-Retrieval Optimisation 预检索优化
Pre-retrieval techniques include improving the quality of indexed data and chunk optimisation. This step could also called Enhancing Semantic Representations 预检索技术包括提高索引数据的质量和块优化。此步骤也可称为增强语义表示
Enhancing data granularity 增强数据粒度
**Improve quality of Data **提高数据质量
'Garbage in, garbage out' "垃圾进,垃圾出"
Data cleaning plays a crucial role in the RAG framework. The performance of your RAG solution depends on how well the data is cleaned and organized. Remove unnecessary information such as special characters, unwanted metadata, or text. 数据清理在RAG框架中起着至关重要的作用。您的RAG解决方案的性能取决于数据被清理和组织得有多好。删除不必要的信息,如特殊字符、不需要的元数据或文本。
- Remove irrelevant text/document: Eliminated all the irrelevant documents that we don't need LLM to answer. Also remove noise data, this includes removing special characters, stop words (common words like "the" and "a"), and HTML tags.
- 删除无关文本/文档:消除所有我们不需要LLM回答的无关文档。还要删除噪声数据,包括删除特殊字符、停用词(如"the"和"a"等常见词)和HTML标签。
- Identify and correct errors: This includes spelling mistakes, typos, and grammatical errors.
- 识别和纠正错误:包括拼写错误、打字错误和语法错误。
- Replacing pronouns with names in split chunks can enhance semantic significance during retrieval.
- 在分割块中用名称替换代词可以增强检索过程中的语义重要性。
Adding Metadata 添加元数据
Adding metadata, such as concept and level tags, to improve the quality of indexed data. 添加元数据,如概念和级别标签,以提高索引数据的质量。
Adding metadata information involves integrating referenced metadata, such as dates and purposes, into chunks for filtering purposes, and incorporating metadata like chapters and subsections of references to improve retrieval efficiency. 添加元数据信息涉及将引用的元数据(如日期和目的)集成到块中以用于过滤目的,并包含像章节和参考文献子章节这样的元数据以提高检索效率。
Here are some scenarios where metadata is useful: 以下是元数据有用的一些场景:
- If you search for items and recency is a criterion, you can sort over a date metadata
- 如果您搜索项目并且时效性是标准,您可以按日期元数据排序
- If you search over scientific papers and you know in advance that the information you're looking for is always located in a specific section, say the experiment section for example, you can add the article section as metadata for each chunk and filter on it to match experiments only
- 如果您搜索科学论文并且您提前知道要查找的信息总是位于特定部分,比如实验部分,您可以将文章部分作为每个块的元数据添加,并对其进行过滤以仅匹配实验
Metadata is useful because it brings an additional layer of structured search on top vector search. 元数据很有用,因为它在向量搜索之上带来了额外的结构化搜索层。
Optimizing index structures 优化索引结构
- Knowledge Graphs or Graph Neural Network Indexing
- 知识图谱或图神经网络索引
Incorporating information from the graph structure to capture relevant context by leveraging relationships between nodes in a graph data index. 从图结构中整合信息,通过利用图数据索引中节点之间的关系来捕获相关上下文。
- Vector Indexing
- 向量索引
Chunking Optimisation 块优化
Choosing the right chunk_size is a critical decision that can influence the efficiency and accuracy of a RAG system in several ways: 选择正确的chunk_size是一个关键决策,可以通过多种方式影响RAG系统的效率和准确性:
Relevance and Granularity 相关性和粒度 A small chunk_size, like 128, yields more granular chunks. This granularity, however, presents a risk: vital information might not be among the top retrieved chunks, especially if the similarity_top_k setting is as restrictive as 2. Conversely, a chunk size of 512 is likely to encompass all necessary information within the top chunks, ensuring that answers to queries are readily available. 较小的chunk_size,如128,会产生更多粒度的块。然而,这种粒度带来了风险:重要信息可能不在检索到的前几个块中,特别是如果similarity_top_k设置为2这样严格的值。相反,512的块大小可能会在前几个块中包含所有必要信息,确保查询的答案随时可用。
Response Generation Time 响应生成时间 As the chunk_size increases, so does the volume of information directed into the LLM to generate an answer. While this can ensure a more comprehensive context, it might also slow down the system. 随着chunk_size的增加,输入到LLM中生成答案的信息量也会增加。虽然这可以确保更全面的上下文,但也可能会减慢系统速度。
Challenges 挑战 If your chunk is too small, it may not include all the information the LLM needs to answer the user's query; if the chunk is too big, it may contain too much irrelevant information that confuses the LLM or may be too big to fit into the context size. 如果您的块太小,可能不包含LLM回答用户查询所需的所有信息;如果块太大,可能包含太多无关信息,使LLM困惑,或者可能太大而无法适应上下文大小。
Task Specific Chunking 特定任务的块分割 Based on downstream task optimal length of the chunk need to determine and how much overlap you want to have for each chunk. 基于下游任务,需要确定块的最佳长度以及每个块想要有多少重叠。
High-level tasks like summarization requires bigger chunk size and low-level tasks like coding requires smaller chunks 高级任务如摘要需要更大的块大小,而低级任务如编码需要更小的块
Chunking Techniques 块分割技术
Small2big or Parent Ducument Retrieval Small2big或父文档检索
The ParentDocumentRetriever strikes that balance by splitting and storing small chunks of data. During retrieval, it first fetches the small chunks but then looks up the parent ids for those chunks and returns those larger documents to the LLM
ParentDocumentRetriever通过分割和存储小块数据来达到这种平衡。在检索过程中,它首先获取小块,然后查找这些块的父ID,并将那些较大的文档返回给LLM
It utilizes small text blocks during the initial search phase and subsequently provides larger related text blocks to the language model for processing. 它在初始搜索阶段利用小文本块,随后为语言模型提供更大的相关文本块进行处理。
Recursive retrieval involves acquiring smaller chunks during the initial retrieval phase to capture key semantic meanings. Subsequently, larger chunks containing more contextual information are provided to the LLM in later stages of the process. This two-step retrieval method helps to strike a balance between efficiency and the delivery of contextually rich responses. 递归检索涉及在初始检索阶段获取较小的块以捕获关键语义含义。随后,在过程的后期阶段,将包含更多上下文信息的较大块提供给LLM。这种两步检索方法有助于在效率和提供上下文丰富的响应之间取得平衡。
Steps: 步骤:
- The process involves broken down of original large document into both smaller, more manageable units referred to as child documents and larger chunks called Parent document.
- 该过程涉及将原始大文档分解为更小、更易管理的单元(称为子文档)和称为父文档的较大块。
- It focus on creating embeddings for each of these child documents, these embeddings richer and more detailed than each of the entire parent chunk embedding. It helps the framework to identify the most relevant child document that contains information related to the user's query.
- 它专注于为每个子文档创建嵌入,这些嵌入比整个父块嵌入更丰富、更详细。它帮助框架识别包含与用户查询相关信息的最相关子文档。
- Once the alignment with a child document is established then it retrieves the entire parent document associated with that child. In the image shown finally parent chunks got retrieved.
- 一旦与子文档建立对齐,它就会检索与该子文档关联的整个父文档。在所示图像中,最终检索到了父块。
- This retrieval of the parent document is significant because it provides a broader context for understanding and responding to the user's query. Instead of relying solely on the content of the child document, the framework now has access to the entire parent document.
- 检索父文档很重要,因为它为理解和响应用户查询提供了更广泛的上下文。框架现在可以访问整个父文档,而不仅仅依赖于子文档的内容。
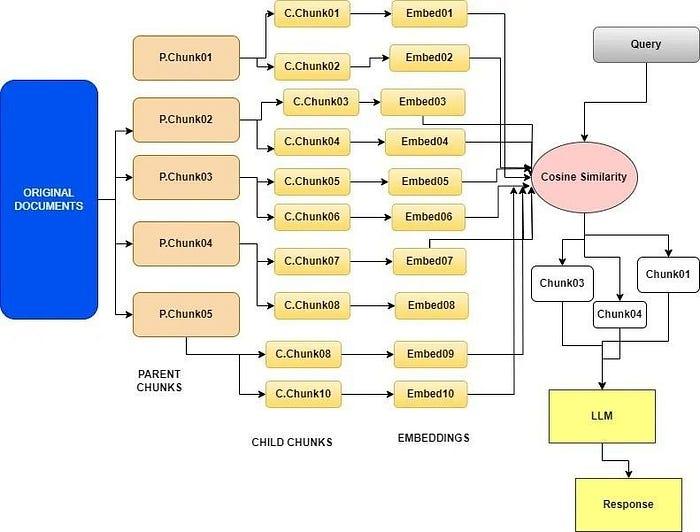
Small2big or Parent Ducument Retrieval chunking technique Small2big或父文档检索块分割技术
Sentence Window Retrieval 句子窗口检索
This chunking technique is very similar to above. The core idea behind Sentence Window Retrieval is to selectively fetch context from a custom knowledge base based on the query and then utilize a broader version of this context for more robust text generation. 这种块分割技术与上述技术非常相似。句子窗口检索背后的核心思想是根据查询从自定义知识库中有选择地获取上下文,然后利用更广泛的上下文版本进行更强大的文本生成。
Get Luv Bansal's stories in your inbox 在您的收件箱中获取Luv Bansal的故事
Join Medium for free to get updates from this writer. 免费加入Medium以获取此作者的更新。
This process involves embedding a limited set of sentences for retrieval, with the additional context surrounding these sentences, referred to as "window context," stored separately and linked to them. Once the top similar sentences are identified, this context is reintegrated just before these sentences are sent to the Large Language Model (LLM) for generation, thereby enriching overall contextual comprehension. 此过程涉及嵌入有限的句子集进行检索,这些句子周围的额外上下文(称为"窗口上下文")单独存储并与之链接。一旦识别出最相似的句子,此上下文就会在这些句子发送给大语言模型(LLM)生成之前重新整合,从而丰富整体上下文理解。
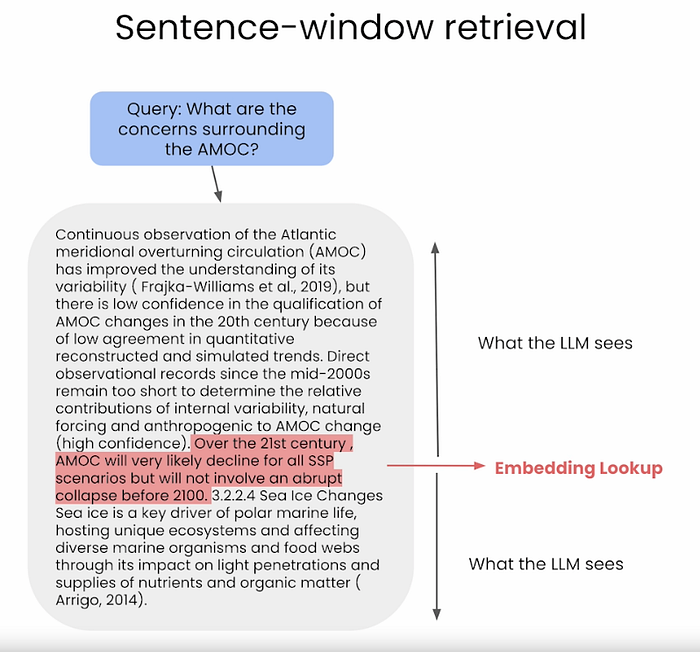
Explains how Sentence Window Retrieval works 解释句子窗口检索如何工作
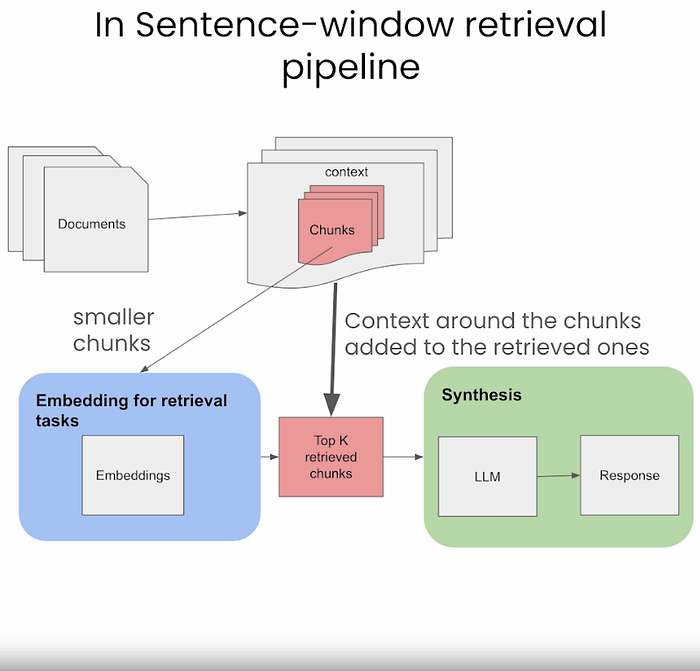
Sentence Window Retrieval chunking technique in RAG RAG中的句子窗口检索块分割技术
Retrieval Optimisation 检索优化
This is the most important part of RAG workflow which includes retrieving documents from the vector store based on user query. This step could also called Aligning Queries and Documents. 这是RAG工作流程中最重要的部分,包括根据用户查询从向量存储中检索文档。此步骤也可称为对齐查询和文档。
Query Rewriting 查询重写
Query rewriting is a fundamental approach for aligning the semantics of a query and a document. 查询重写是使查询和文档语义对齐的基本方法。
In this process, we leverage Language Model (LLM) capabilities to rephrase the user's query and give it another shot. It's important to note that two questions that might look the same to a human may not appear similar in the embedding space. 在此过程中,我们利用语言模型(LLM)功能重新表述用户查询并再次尝试。需要注意的是,对人类来说看起来相同的两个问题在嵌入空间中可能不相似。
MultiQuery Retrievers 多查询检索器 The Multi-query Retrieval method utilizes LLMs to generate multiple queries from different perspectives for a given user input query, advantageous for addressing complex problems with multiple sub-problems. 多查询检索方法利用LLM从不同角度为给定的用户输入查询生成多个查询,有利于解决具有多个子问题的复杂问题。
For each query, it retrieves a set of relevant documents and takes the unique union across all queries to get a larger set of potentially relevant documents. 对于每个查询,它检索一组相关文档,并在所有查询中取唯一并集以获得更大的潜在相关文档集。
By generating multiple perspectives on the same question, the MultiQuery Retriever might be able to overcome some of the limitations of the distance-based retrieval and get a richer set of results. 通过从多个角度生成相同的问题,多查询检索器可能能够克服基于距离检索的一些限制,并获得更丰富的结果集。
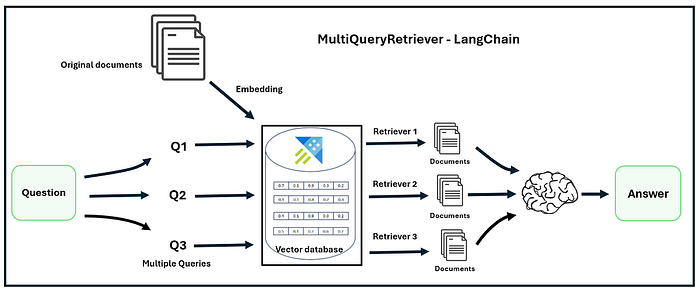
MultiQuery Retriever 多查询检索器
Hyde or Query2doc Hyde或Query2doc Both Hyde and Query2doc are similar query rewriting optimisations. Given that search queries are often short, ambiguous, or lack necessary background information, LLMs can provide relevant information to guide retrieval systems, as they memorize an enormous amount of knowledge and language patterns by pre-training on trillions of tokens. Hyde和Query2doc都是类似的查询重写优化。鉴于搜索查询通常很短、模糊或缺乏必要的背景信息,LLM可以提供相关信息来指导检索系统,因为它们通过在数万亿个标记上预训练记住了大量的知识和语言模式。
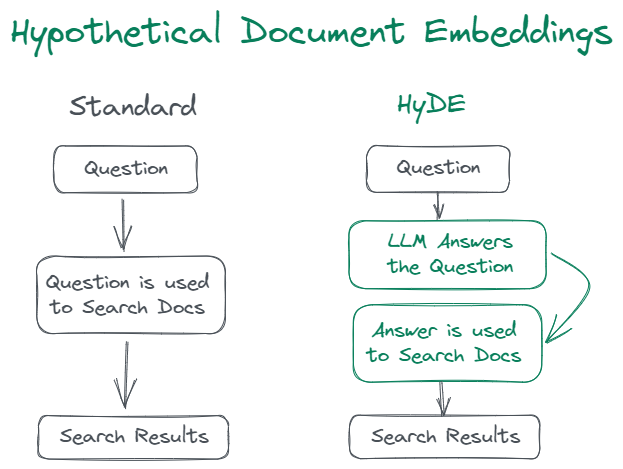
Fig, show difference between Standard and Hyde approach 图,显示标准方法和Hyde方法之间的差异
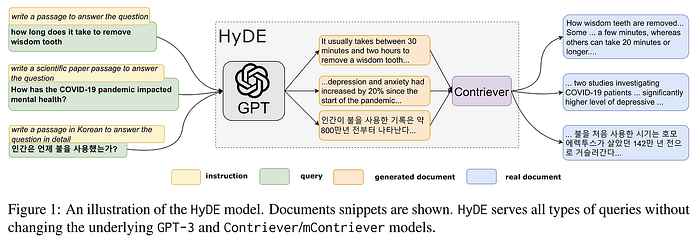
Image Source: Precise Zero-Shot Dense Retrieval without Relevance Labels 图片来源:无相关性标签的精确零样本密集检索
StepBack-prompt StepBack提示 The StepBack-prompt approach encourages the language model to think beyond specific examples and focus on broader concepts and principles. StepBack提示方法鼓励语言模型超越具体示例,关注更广泛的概念和原则。
This template replicates the "Step-Back" prompting technique that improves performance on complex questions by first asking a "step back" question. This technique can be combined with standard question-answering RAG applications by retrieving information for both the original and step-back questions. Below is an example of a step-back prompt. 此模板复制了"后退"提示技术,通过首先询问"后退"问题来提高复杂问题的性能。此技术可以与标准问答RAG应用程序结合使用,为原始问题和后退问题都检索信息。以下是后退提示的示例。
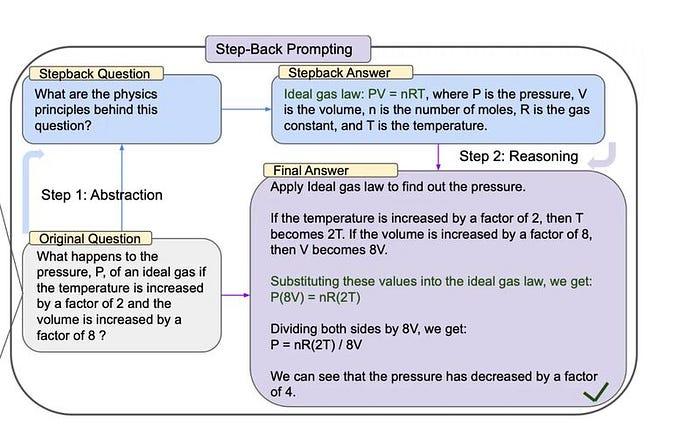
Image Source: TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS 图片来源:后退一步:通过大语言模型中的抽象激发推理
Fine-tuning Embedding 微调嵌入
Fine-tuning embedding models significantly impact the relevance of retrieved content in RAG systems. This process involves customizing embedding models to enhance retrieval relevance in domain-specific contexts, especially for professional domains dealing with evolving or rare terms. 微调嵌入模型显著影响RAG系统中检索内容的相关性。此过程涉及定制嵌入模型以增强特定领域上下文中的检索相关性,特别是对于处理演变或罕见术语的专业领域。
Generating synthetic dataset for training and evaluation 生成用于训练和评估的合成数据集 The key idea here is that training data for fine-tuning can be generated using language models like GPT-3.5-turbo to formulate questions grounded on document chunks. This allows us to generate synthetic positive pairs of (query, relevant documents) in a scalable way without requiring human labellers. Final dataset will be pairs of questions and text chunks. 这里的关键思想是,可以使用像GPT-3.5-turbo这样的语言模型生成用于微调的训练数据,以制定基于文档块的问题。这使我们能够以可扩展的方式生成(查询,相关文档)的合成正例对,而无需人工标注。最终数据集将是问题和文本块的对。
Fine-tune Embedding 微调嵌入 Fine-tune any embedding model on the generated training Dataset 在生成的训练数据集上微调任何嵌入模型
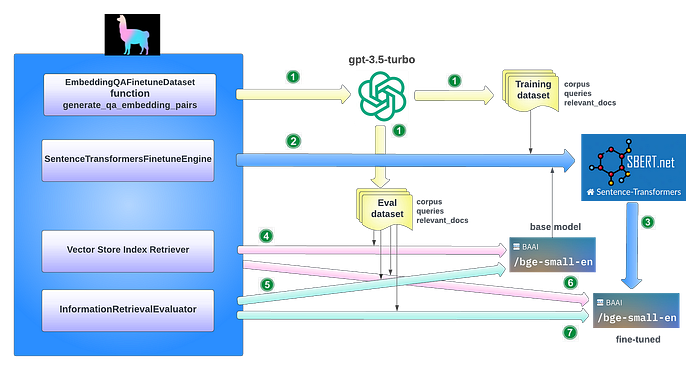
Fine-tune embedding model by synthetic generated dataset using GPT 使用GPT通过合成生成的数据集微调嵌入模型
Hybrid Search Exploration 混合搜索探索
The RAG system optimizes its performance by intelligently integrating various techniques, including keyword based search, semantic search, and vector search. RAG系统通过智能整合各种技术来优化其性能,包括基于关键字的搜索、语义搜索和向量搜索。
This approach leverages the unique strengths of each method to accommodate diverse query types and information needs, ensuring consistent retrieval of highly relevant and context-rich information. The use of hybrid search serves as a robust supplement to retrieval strategies, thereby enhancing the overall efficacy of the RAG pipeline. 这种方法利用每种方法的独特优势来适应不同的查询类型和信息需求,确保一致检索高度相关和上下文丰富的信息。混合搜索的使用作为检索策略的有力补充,从而提高RAG管道的整体效果。
Common Example 常见示例 The most common pattern is to combine a sparse retriever (like BM25) with a dense retriever (like embedding similarity), because their strengths are complementary. It is also known as "hybrid search". The sparse retriever is good at finding relevant documents based on keywords, while the dense retriever is good at finding relevant documents based on semantic similarity. 最常见的模式是将稀疏检索器(如BM25)与密集检索器(如嵌入相似性)结合,因为它们的优势是互补的。这也被称为"混合搜索"。稀疏检索器擅长基于关键字查找相关文档,而密集检索器擅长基于语义相似性查找相关文档。
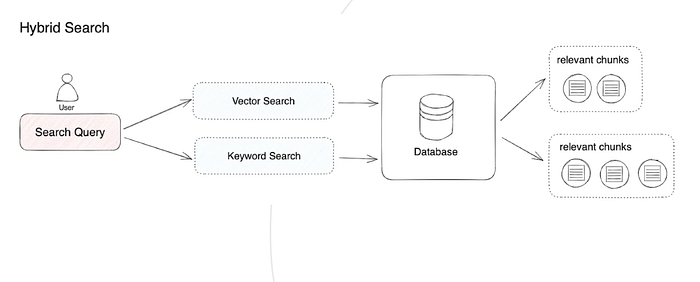
Hybrid Search Retrieval 混合搜索检索
Post-Retrieval Optimisation 后检索优化
Re-Ranking 重排序
Reranking retrieval results before sending them to the LLM has significantly improved RAG performance. 在将检索结果发送给LLM之前重新排序显著提高了RAG性能。
A high score in vector similarity search does not mean that it will always have the highest relevance. 向量相似性搜索中的高分并不意味着它总是具有最高的相关性。
The core concept involves re-arranging document records to prioritize the most relevant items at the top, thereby limiting the total number of documents. This not only resolves the challenge of context window expansion during retrieval but also enhances retrieval efficiency and responsiveness. 核心概念涉及重新排列文档记录,将最相关的项目优先排在顶部,从而限制文档总数。这不仅解决了检索过程中上下文窗口扩展的挑战,还提高了检索效率和响应速度。
Increase the similarity_top_k in the query engine to retrieve more context passages, which can be reduced to top_n after reranking. 增加查询引擎中的similarity_top_k以检索更多上下文段落,这些段落在重新排序后可以减少到top_n。
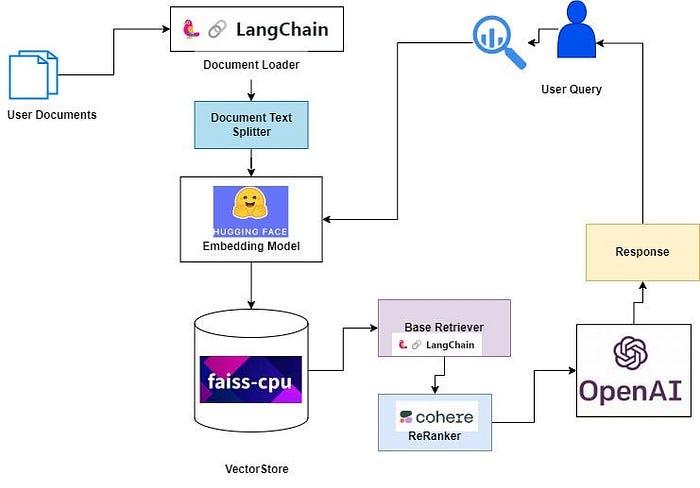
Re-Ranking the retrieved document using Cohere Reranker 使用Cohere重排序器重新排序检索到的文档
Prompt Compression 提示压缩
Noise in retrieved documents adversely affects RAG performance therefore, information most relevant to a query may be buried in a document with a lot of irrelevant text. Passing that full document through your application can lead to more expensive LLM calls and poorer responses. 检索到的文档中的噪声会对RAG性能产生不利影响,因此与查询最相关的信息可能埋藏在包含大量无关文本的文档中。将完整文档通过您的应用程序可能会导致更昂贵的LLM调用和较差的响应。
Here, the emphasis lies in compressing irrelevant context, highlighting pivotal paragraphs, and reducing the overall context length. 这里,重点在于压缩无关上下文,突出关键段落,并减少整体上下文长度。
Contextual compression 上下文压缩 Contextual compression is meant to fix this. The idea is simple: instead of immediately returning retrieved documents as-is, it can compress them using the context of the given query, so that only the relevant information is returned. "Compressing" here refers to both compressing the contents of an individual document and filtering out documents wholesale. 上下文压缩旨在解决这个问题。这个想法很简单:不是立即按原样返回检索到的文档,而是可以使用_给定查询的上下文_来压缩它们,这样只返回相关信息。这里的"压缩"既指压缩单个文档的内容,也指整体过滤掉文档。
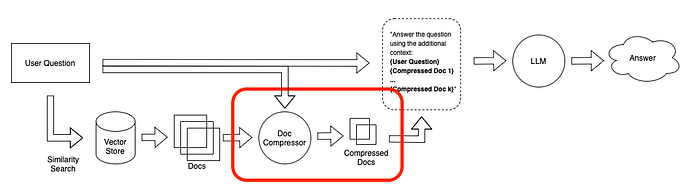
Contextual compression 上下文压缩
Doc Compressor is a small language models to calculate prompt mutual information of user query and retrieved document, estimating element importance. Doc Compressor是一个小型语言模型,用于计算用户查询和检索文档的提示互信息,估计元素重要性。
Modular RAG 模块化RAG
Modular RAG integrates various methods to enhance different component of RAG, such as incorporating a search module for similarity retrieval and applying a fine-tuning approach in the retriever 模块化RAG整合了各种方法来增强RAG的不同组件,例如结合用于相似性检索的搜索模块和在检索器中应用微调方法
RAG Fusion RAG融合
RAG Fusion combines 2 approaches: RAG融合结合了2种方法:
- Multi-Query Retrieval 多查询检索 Utilizes LLMs to generate multiple queries from different perspectives for a given user input query, advantageous for addressing complex problems with multiple sub-problems. 利用LLM从不同角度为给定的用户输入查询生成多个查询,有利于解决具有多个子问题的复杂问题。
- Rerank Retrieved Documents 重新排序检索到的文档 Re-rank all the retrieved documents and removed all documents with low relevant scores 重新排序所有检索到的文档,并删除所有相关性得分低的文档
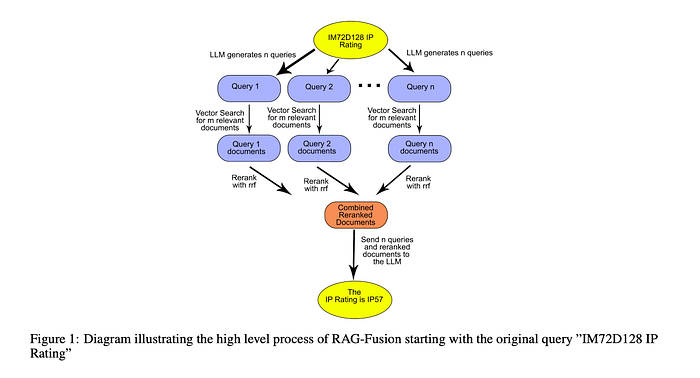
Image source: RAG-FUSION: A NEW TAKE ON RETRIEVAL-AUGMENTED GENERATION 图片来源:RAG融合:检索增强生成的新视角
This advanced technique guarantees search results that match the user's intentions, whether they are obvious or not. It helps users find more insightful and relevant information. 这种高级技术保证了匹配用户意图的搜索结果,无论这些意图是否明显。它帮助用户找到更有洞察力和相关的信息。
Final thoughts 最后思考
This article discusses various techniques to optimize each part of the RAG pipeline and enhance the overall RAG pipeline. You can use one or multiple of these techniques in your RAG pipeline, making it more accurate and more efficient. I hope these techniques can help you build a better RAG pipeline for your app. 本文讨论了优化RAG管道每个部分和增强整体RAG管道的各种技术。您可以在RAG管道中使用这些技术中的一种或多种,使其更准确和高效。我希望这些技术能帮助您为应用程序构建更好的RAG管道。
Medium's Boost / AI Life Hacks / FREE GPTs alternative / Video2Wolds
Medium的提升 / AI生活技巧 / 免费GPTs替代品 / Video2Wolds
[初识]为什么 RAG 管道会失败?高级 RAG 模式 — 第 1 部分
Explore the reasons why RAG pipelines fail, covering retrieval, augmentation, and generation problems. 探索 RAG 管道失败的原因,涵盖检索、增强和生成问题。
生产就绪的 RAG 应用程序的 12 种调优策略指南
A comprehensive guide on tuning strategies for production-ready RAG applications, covering both ingestion and inferencing stages