Advanced RAG Architecture | 高级RAG架构
深入了解高级RAG架构的设计和实现。Understanding advanced RAG architecture design and implementation.
Advanced RAG Architecture | 高级RAG架构

15 min read
Mar 23, 2024
What is RAG? | 什么是RAG?
The concept known as 'Retrieval Augmented Generation', abbreviated as RAG, first entered our lives with an academic study published by Meta in 2020. Although the concept has a short history, it has revealed serious potential when combined with large language model technology and is now at the center of generative artificial intelligence, offering us opportunities as the largest commercial use case that can be benefited from in this field.
被称为"检索增强生成"(RAG)的概念首次出现在2020年Meta发布的一项学术研究中。尽管这个概念历史较短,但与大语言模型技术结合后显示出巨大潜力,现在已成为生成式人工智能的核心,为我们提供了该领域最大的商业应用机会。
RAG augments the capability of large language models with masses of data outside the base model, enabling model responses to generate more real, more individual, and more reliable outputs. For this reason, for RAG; We can say that it is a framework that provides functionality to improve the performance of large language models. Thanks to this flexible and powerful framework, RAG has achieved significant growth in the applications of large language models in the corporate field in just 3 years. According to the Retool Report published in 2023, an impressive 36.2% of enterprise big language model use cases now use the RAG framework. RAG combines the power of large language models with structured and unstructured data, making enterprise information access more effective and faster than ever before. In this way, more competent and successful artificial intelligence services can be produced without the need for data science processes such as data preparation required by traditional virtual assistants, while spending minimum labor.
RAG通过使用基础模型之外的大量数据来增强大语言模型的能力,使模型响应能够生成更真实、更个性化、更可靠的输出。因此,对于RAG来说,我们可以说它是一个提供功能以改进大语言模型性能的框架。得益于这个灵活而强大的框架,RAG在企业领域的大语言模型应用中仅用了3年就实现了显著增长。根据2023年发布的Retool报告,令人印象深刻的36.2%的企业大语言模型用例现在使用RAG框架。RAG将大语言模型的力量与结构化和非结构化数据相结合,使企业信息访问比以往任何时候都更有效、更快捷。通过这种方式,可以在最少人工投入的情况下,无需传统虚拟助手所需的数据准备等数据科学流程,就能产生更有能力、更成功的人工智能服务。

How Does RAG Work? | RAG是如何工作的?
A typical RAG process, as pictured below, has a large language model at its core, a collection of corporate documents to be used to feed the model, and prompt engineering infrastructure to improve response generation. RAG workflow; It uses the vector database to find concepts and documents similar to the question asked, and prompt engineering techniques to convert the relevant data into the format expected by the model. This process of RAG makes it a powerful tool for companies looking to leverage existing data repositories for advanced decision-making and information retrieval. To look at the application steps in order:
一个典型的RAG过程如下图所示,其核心是大语言模型,用于为模型提供数据的企业文档集合,以及用于改进响应生成的提示工程基础设施。RAG工作流程使用向量数据库查找与所提问题相似的概念和文档,并使用提示工程技术将相关数据转换为模型期望的格式。RAG的这一过程使其成为希望利用现有数据存储库进行高级决策和信息检索的公司的强大工具。按顺序查看应用步骤:
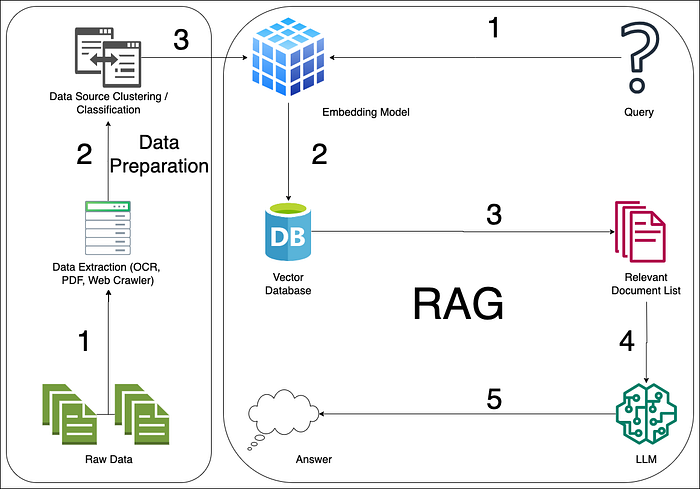
1-Query: The question in text format is sent to the RAG flow through any virtual assistant or interface.
1-查询:文本格式的问题通过任何虚拟助手或界面发送到RAG流程。
2-(Retrieval) Document Search: The model performs a search step to collect relevant information from external sources. These sources may include a database, a set of documents, or even search engine results. The search process aims to find text fragments or documents containing information relevant to the given input or request.
2-(Retrieval) 文档搜索:模型执行搜索步骤以从外部源收集相关信息。这些源可能包括数据库、文档集,甚至是搜索引擎结果。搜索过程旨在找到包含与给定输入或请求相关信息的文本片段或文档。
3-Augmentation: The information obtained during the search phase is then combined with the original input or prompt and enriched by creating a prompt engineering draft that the model can use to create the output. The model is brought to the format expected by the large language model by including external information in this draft created through prompt engineering.
3-Augmentation(增强):在搜索阶段获得的信息随后与原始输入或提示相结合,通过创建模型可用于生成输出的提示工程草稿来丰富内容。通过在通过提示工程创建的草稿中包含外部信息,使模型达到大语言模型期望的格式。
4-Generation: Finally, the model produces the answer by taking into account the received information and the original input. Here, the first form of the question posed to the system, the document obtained from the vector database and other arguments are evaluated together to ensure that the large language model produces the most accurate output text.
4-Generation(生成):最后,模型通过考虑接收到的信息和原始输入来产生答案。在这里,系统提出的问题的初始形式、从向量数据库获得的文档和其他参数一起被评估,以确保大语言模型产生最准确的输出文本。
5-Answering: New content created by the large language model is transferred to the user.
5-回答:大语言模型创建的新内容被传输给用户。
RAG can be useful in a variety of natural language processing tasks, such as question answering, conversation generation, summarization, and more. By incorporating external information, RAG models demonstrate the potential to provide more accurate and informative answers than traditional models that rely solely on the data on which they are trained.
RAG在各种自然语言处理任务中都很有用,如问答、对话生成、摘要等。通过整合外部信息,RAG模型展示了比仅依赖训练数据的传统模型提供更准确和信息丰富的答案的潜力。
RAG is a suitable solution for a wide range of industries and use cases. It facilitates informed decision-making processes by helping to reference information from large databases or document repositories in the finance, legal and healthcare sectors. Additionally, regardless of the sector, RAG in the field of customer service; It is used to power virtual assistants and provide accurate and contextually appropriate answers to user queries. Apart from this, it also has an important place in personalized content creation and recommendation systems by understanding user preferences and historical data.
RAG是适合广泛行业和用例的解决方案。它通过帮助参考金融、法律和医疗保健部门的大型数据库或文档存储库中的信息来促进知情决策过程。此外,无论哪个行业,RAG在客户服务领域都被用来驱动虚拟助手,并为用户提供准确且符合上下文的答案。除此之外,通过了解用户偏好和历史数据,它在个性化内容创建和推荐系统中也占有重要地位。
Differences Between RAG and Traditional Methods | RAG与传统方法的区别
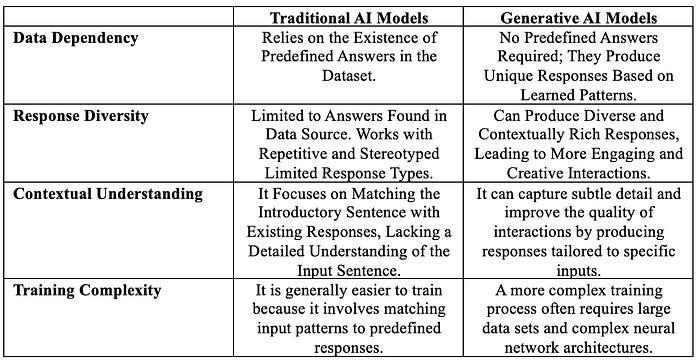
Traditional Models Based on Classification | 基于分类的传统模型
Traditional natural language models are designed to select an appropriate response from a set of predefined responses based on the input query. These models compare input text (a question or query) against a taxonomy set of predefined answers. The system determines the most appropriate response by measuring the similarity between the input and labeled responses using techniques such as supervised learning algorithms or other semantic matching methods. These classification-based models are effective for tasks such as question answering, where answers are often based on static response types and can be easily found in a structured form.
传统的自然语言模型旨在根据输入查询从一组预定义响应中选择适当的响应。这些模型将输入文本(问题或查询)与预定义答案的分类集进行比较。系统通过使用监督学习算法或其他语义匹配方法等技术测量输入和标记响应之间的相似性来确定最适当的响应。这些基于分类的模型对于问答等任务是有效的,其中答案通常基于静态响应类型,并且可以轻松地以结构化形式找到。
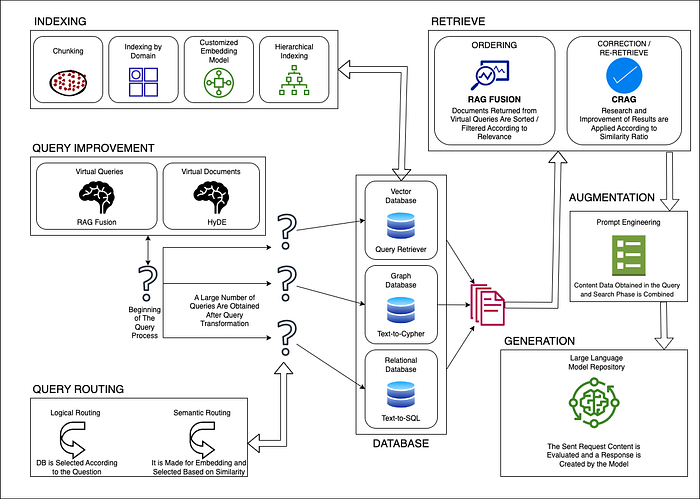
Advanced RAG Architecture Components | 高级RAG架构组件
1. Query Transformation Layer | 查询转换层
In advanced RAG implementations, the query transformation layer plays a crucial role in improving retrieval accuracy. This layer preprocesses user queries to better match the semantic structure of the knowledge base.
在高级RAG实现中,查询转换层在提高检索准确性方面起着至关重要的作用。该层预处理用户查询以更好地匹配知识库的语义结构。
2. Multi-Modal Retrieval | 多模态检索
Modern RAG systems often incorporate multi-modal retrieval capabilities, allowing them to search across different types of data including text, images, and structured data.
现代RAG系统通常包含多模态检索功能,使其能够跨不同类型的数据进行搜索,包括文本、图像和结构化数据。
3. Dynamic Context Window Management | 动态上下文窗口管理
Advanced RAG architectures implement dynamic context window management to optimize the balance between context relevance and computational efficiency.
高级RAG架构实现动态上下文窗口管理,以优化上下文相关性和计算效率之间的平衡。
Implementation Considerations | 实施考虑因素
When implementing advanced RAG architectures, several key factors should be considered:
在实施高级RAG架构时,应考虑几个关键因素:
-
Scalability: The system should be designed to handle increasing amounts of data and user requests.
可扩展性:系统应设计为能够处理不断增加的数据量和用户请求。
-
Latency: Response times should be optimized to provide a seamless user experience.
延迟:应优化响应时间以提供无缝的用户体验。
-
Accuracy: The retrieval and generation components should be fine-tuned to ensure high-quality outputs.
准确性:应微调检索和生成组件以确保高质量的输出。
-
Security: Data privacy and security measures should be implemented to protect sensitive information.
安全性:应实施数据隐私和安全措施以保护敏感信息。
Conclusion | 结论
Advanced RAG architectures represent a significant evolution in the field of generative AI, offering enhanced capabilities for information retrieval and response generation. By combining the power of large language models with sophisticated retrieval mechanisms, these systems provide more accurate, relevant, and contextually appropriate responses to user queries.
高级RAG架构代表了生成式AI领域的重大演进,为信息检索和响应生成提供了增强的功能。通过将大语言模型的力量与复杂的检索机制相结合,这些系统为用户查询提供了更准确、相关和符合上下文的回答。
As the technology continues to evolve, we can expect to see even more sophisticated RAG implementations that further bridge the gap between human knowledge and artificial intelligence capabilities.
随着技术的不断发展,我们可以期待看到更加复杂的RAG实现,进一步弥合人类知识和人工智能能力之间的差距。