SPLADE for Sparse Vector Search Explained | Pinecone | SPLADE稀疏向量搜索详解
了解SPLADE如何结合稀疏和密集检索的优势,实现更高效的向量搜索。Understanding how SPLADE combines the benefits of sparse and dense retrieval for more efficient vector search.
SPLADE for Sparse Vector Search Explained | Pinecone | SPLADE稀疏向量搜索详解
Google, Netflix, Amazon, and many more big tech companies all have one thing in common. They power their search and recommendation systems with "vector search".
谷歌、网飞、亚马逊等许多大型科技公司都有一个共同点。它们都使用"向量搜索"来驱动其搜索和推荐系统。
Before modern vector search, we had the "traditional" bag of words (BOW) methods. That is, we take a set of "documents" to be retrieved (like web pages on Google). Each document is transformed into a set (bag) of words, and use this to populate a sparse "frequency vector". Popular algorithms for this include TF-IDF and BM25.
在现代向量搜索之前,我们使用的是_"传统"的词袋(BOW)方法。也就是说,我们获取一组要检索的"文档"(比如谷歌上的网页)。每个文档都被转换成一组(袋)词汇,并用这个来填充稀疏的"频率向量"_。这方面的流行算法包括TF-IDF和BM25。
These sparse vectors are hugely popular in information retrieval thanks to their efficiency, interpretability, and exact term matching. Yet, they're far from perfect.
这些稀疏向量在信息检索中非常流行,因为它们具有高效性、可解释性和精确的术语匹配。然而,它们_远非完美_。
Our nature as human beings does not align with sparse vector search. When searching for information, we rarely know the exact terms that will be contained in the documents we're looking for.
作为人类,我们的本性与稀疏向量搜索并不一致。在搜索信息时,我们很少知道要查找的文档中会包含哪些确切的术语。
Dense embedding models offer some help in this direction. By using dense models, we can search based on "semantic meaning" rather than term matching. However, these models could be better.
密集嵌入模型在这方面提供了一些帮助。通过使用密集模型,我们可以基于_"语义含义"_而不是术语匹配来进行搜索。然而,这些模型还有改进的空间。
We need vast amounts of data to fine-tune dense embedding models; without this, they lack the performance of sparse methods. This is problematic for niche domains where data is hard to find and domain-specific terminology is important.
我们需要大量数据来微调_密集嵌入模型_;没有这些数据,它们就缺乏稀疏方法的性能。这对于数据难以获取且领域特定术语很重要的小众领域来说是个问题。
In the past, there have been a range of band aid solutions for dealing with this; ranging from complex and (still not perfect) two-stage retrieval systems, to query and document expansion or rewrite methods (as we will explore later). However, none of these came close to being truly robust solutions.
过去,有各种_"创可贴"_解决方案来处理这个问题;从复杂且(仍然不完美)的两阶段检索系统,到查询和文档扩展或重写方法(我们稍后会探讨)。然而,这些都不是真正稳健的解决方案。
Fortunately, plenty of progress has been made in making the most of both worlds. A merger of sparse and dense retrieval is now possible through hybrid search, and learnable sparse embeddings help minimize the traditional drawbacks of sparse retrieval.
幸运的是,在充分利用两个世界方面已经取得了很大进展。通过混合搜索,稀疏和密集检索的结合现在成为可能,而_可学习_的稀疏嵌入有助于最小化稀疏检索的传统缺点。
This article will cover the latest in learnable sparse embeddings with SPLADE — the Sparse Lexical and****Expansion model [1].
本文将介绍SPLADE中最新的可学习稀疏嵌入——Sparse Lexical and****Expansion模型[1]。
Sparse and Dense | 稀疏与密集
In information retrieval, vector embeddings represent documents and queries in a numerical vector format. This format allows us to search a vector database and identify similar vectors.
在信息检索中,向量嵌入以数值向量格式表示文档和查询。这种格式使我们能够在向量数据库中搜索并识别相似的向量。
Sparse and dense vectors are two different forms of this representation, each with pros and cons.
稀疏向量和密集向量是这种表示的两种不同形式,各有优缺点。

Sparse vectors consist of many zero values with very few non-zero values.
稀疏向量由许多零值和很少的非零值组成。
Sparse vectors like TF-IDF or BM25 have high dimensionality and contain very few non-zero values (hence, they are called "sparse"). There are decades of research behind sparse vectors. Resulting in compact data structures and many efficient retrieval algorithms designed specifically for these vectors.
像TF-IDF或BM25这样的稀疏向量具有高维度,包含很少的非零值(因此被称为_"稀疏"_)。稀疏向量背后有几十年的研究。这产生了紧凑的数据结构和许多专门为这些向量设计的高效检索算法。
Dense vectors are lower-dimensional but information-rich, with non-zero values in most-or-all dimensions. These are typically built using neural network models like transformers and, through this, can represent more abstract information like the semantic meaning behind some text.
密集向量是低维度但信息丰富的,在大多数或所有维度中都有非零值。这些通常使用神经网络模型(如变压器)构建,通过这种方式可以表示更抽象的信息,如某些文本背后的_语义含义_。
Generally speaking, the pros and cons of both methods can be outlined as follows:
一般来说,这两种方法的优缺点可以概括如下:
Sparse | 稀疏
Pros | 优点:
- Typically faster retrieval | 通常检索更快
- Good baseline performance | 良好的基线性能
- Don't need model fine-tuning | 不需要模型微调
- Exact matching of terms | 精确匹配术语
Cons | 缺点:
- Performance cannot be improved significantly over baseline | 性能无法在基线基础上显著提高
- Suffers from vocabulary mismatch problem | 遭受词汇不匹配问题
Dense | 密集
Pros | 优点:
- Can outperform sparse with fine-tuning | 通过微调可以超越稀疏
- Search with human-like abstract concepts | 使用类似人类的抽象概念进行搜索
- Multi-modality (text, images, audio, etc.) and cross-modal search (e.g., text-to-image) | 多模态(文本、图像、音频等)和跨模态搜索(如文本到图像)
Cons | 缺点:
- Requires training data, difficult to do in low-resource scenarios | 需要训练数据,在资源匮乏的情况下难以实现
- Does not generalize well, particularly for niche terminology | 泛化能力不强,特别是对于小众术语
- Requires more compute and memory than sparse | 需要比稀疏更多的计算和内存
- No exact match | 没有精确匹配
- Not easily interpretable | 不易解释
Ideally, we want the merge the best of both, but that's hard to do.
理想情况下,我们希望融合两者的优点,但这很难做到。
Two-Stage Retrieval | 两阶段检索
A typical approach to handling this is implementing a two-stage retrieval and ranking system. In this scenario, we use two distinct stages to retrieve and rank relevant documents for a given query.
处理这个问题的典型方法是实现两阶段检索和排名系统。在这种情况下,我们使用两个不同的阶段来检索和排名给定查询的相关文档。
In the first stage, the system uses a sparse retrieval method to retrieve a large set of candidate documents. These are then passed to the second stage, where we use a dense model to rerank the results based on their relevance to the query.
在第一阶段,系统使用稀疏检索方法检索大量候选文档。然后将这些文档传递到第二阶段,在那里我们使用密集模型根据它们与查询的相关性重新排名结果。
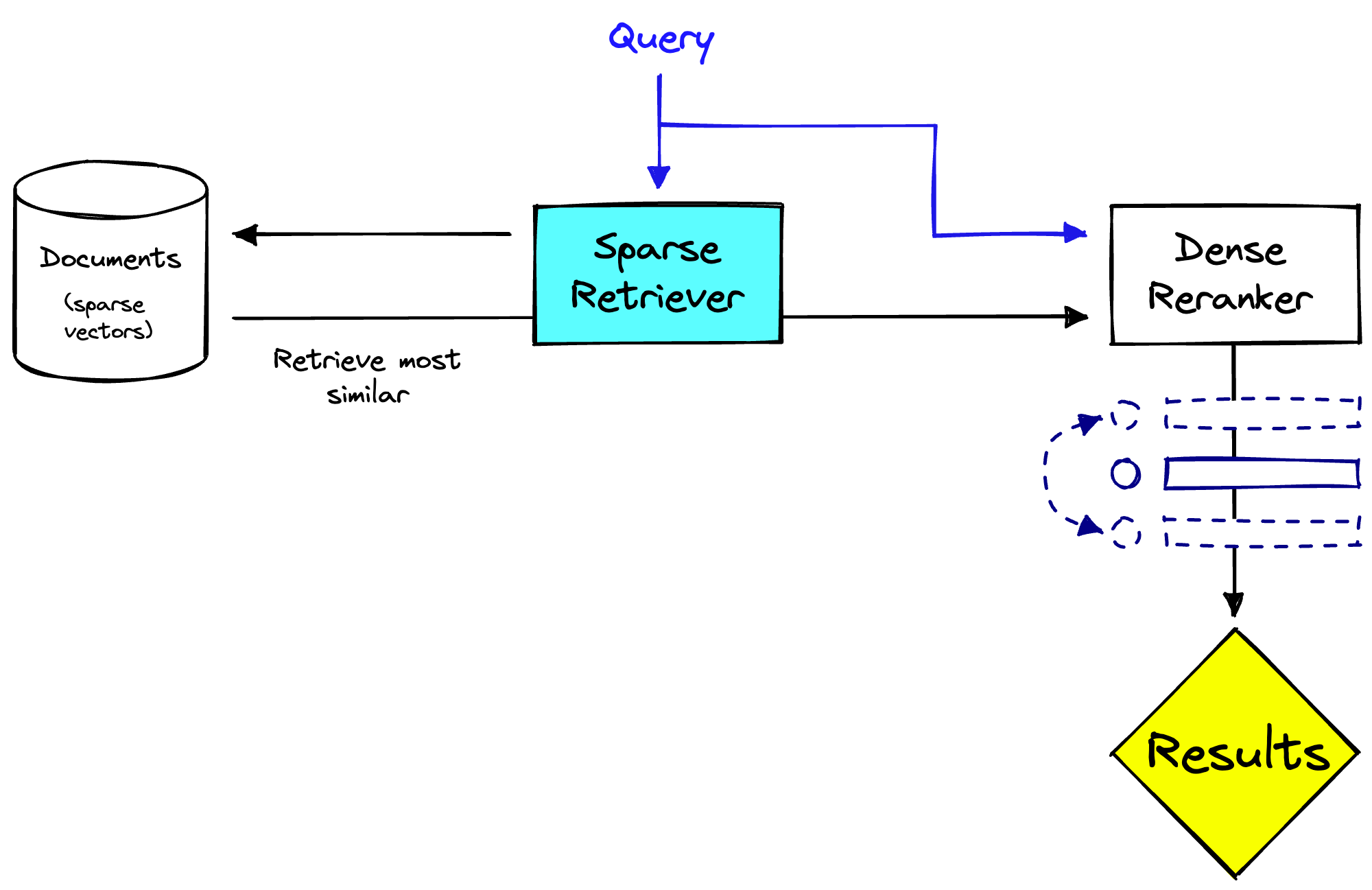
Two-stage retrieval system with a sparse retriever and dense reranker.
具有稀疏检索器和密集重排器的两阶段检索系统。
There are benefits to this, (1) we apply the sparse model to the full set of documents to retrieve, which is more efficient. Then (2) we rerank the now smaller set of documents with the slower dense model, which can be more accurate. From this, we can return much more relevant results to users. Another benefit is that this reranking stage is detached from the retrieval system, this can be useful when the retrieval system is multi-purpose.
这样做的好处有:(1)我们将稀疏模型应用于完整的文档集进行检索,这样更高效。然后(2)我们用较慢的密集模型重新排名现在较小的文档集,这_可以_更准确。通过这种方式,我们可以向用户返回更相关的结果。另一个好处是重新排名阶段与检索系统分离,当检索系统是多用途时这很有用。
However, it isn't perfect. Two stages of retrieval and reranking can be slower than a single-stage system using approximate search algorithms. Having two stages is more complex and therefore brings more engineering challenges. Finally, the performance relies on the first-stage retriever returning relevant results; if nothing useful is returned, the reranking cannot help.
然而,这并不完美。两阶段的检索和重新排名可能比使用近似搜索算法的单阶段系统更慢。有两个阶段更复杂,因此带来更多工程挑战。最后,性能依赖于第一阶段检索器返回相关结果;如果没有返回有用的结果,重新排名就无法提供帮助。
Improving Single-Stage Systems | 改进单阶段系统
Because of the two-stage retrieval drawbacks, much work has been put into improving single-stage retrieval systems.
由于两阶段检索的缺点,大量工作投入到改进_单阶段_检索系统。
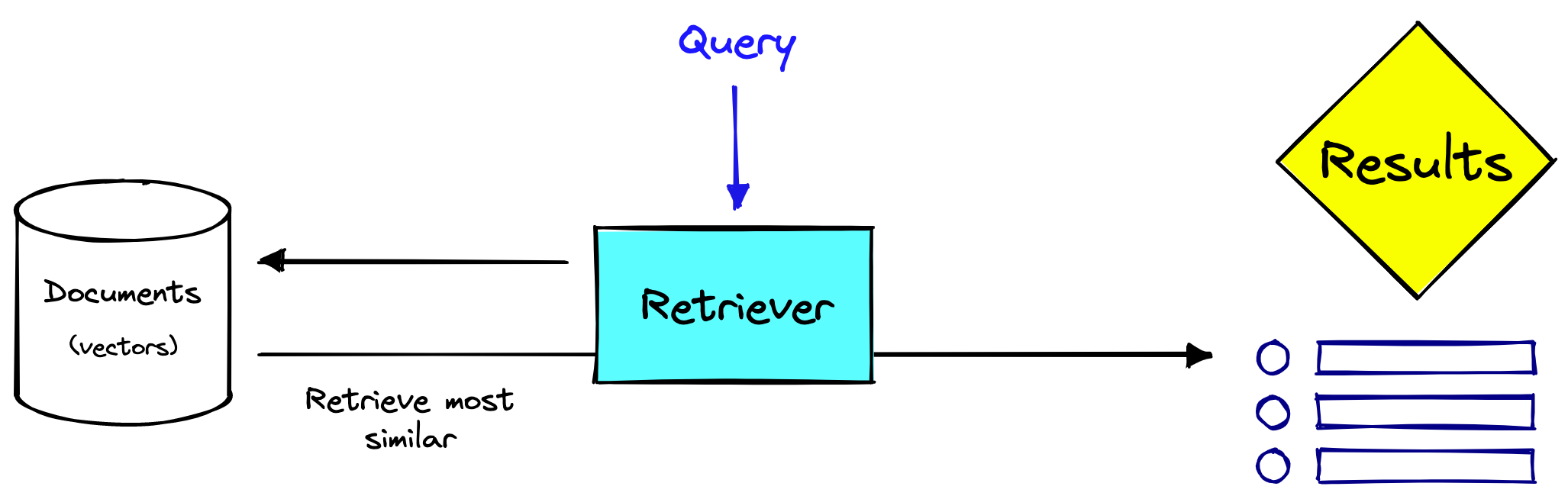
A single stage retrieval system. Note that the retriever may be sparse, dense, or even both.
单阶段检索系统。注意检索器可以是稀疏的、密集的,甚至两者兼有。
A part of that is the research into more robust and learnable sparse embedding models — and one of the most performant models in this space is SPLADE.
其中一部分是研究更稳健和可学习的稀疏嵌入模型——而这一领域性能最好的模型之一就是SPLADE。
The idea behind the Sparse Lexical and****Expansion models is that a pretrained language model like BERT can identify connections between words/sub-words (called word-pieces or "terms" in this article) and use that knowledge to enhance our sparse vector embedding.
Sparse Lexical and****Expansion模型背后的理念是,像BERT这样的预训练语言模型可以识别词汇/子词汇(在本文中称为_词片_或"术语")之间的联系,并利用这些知识来增强我们的稀疏向量嵌入。
This works in two ways, it allows us to weigh the relevance of different terms (something like the will carry less relevance than a less common word like orangutan). And it enables term expansion: the inclusion of alternative but relevant terms beyond those found in the original sequence.
这通过两种方式起作用,它允许我们权衡不同术语的相关性(像the这样的词比像orangutan这样不太常见的词相关性更低)。并且它支持_术语扩展_:包含原始序列中未找到的替代但相关的术语。

Term expansion allows us to identify relevant but different terms and use them in the sparse vector retrieval step.
术语扩展允许我们识别相关但不同的术语,并在稀疏向量检索步骤中使用它们。
The most significant advantage of SPLADE is not necessarily that it can do term expansion but instead that it can learn term expansions. Traditional methods required rule-based term expansion which is time-consuming and fundamentally limited. Whereas SPLADE can use the best language models to learn term expansions and even tweak them based on the sentence context.
SPLADE最重要的优势不一定在于它能够_进行_术语扩展,而在于它能够_学习_术语扩展。传统方法需要基于规则的术语扩展,这既耗时_又_从根本上受限。而SPLADE可以使用最佳语言模型来学习术语扩展,甚至根据句子上下文进行调整。

Despite having a query and document with many relevant terms, because they are not "exact matches" they are not identified.
尽管查询和文档有许多相关术语,但由于它们不是"精确匹配",所以未被识别。
How SPLADE Works | SPLADE的工作原理
SPLADE models are bi-encoder transformer models that are initialized from a masked language model like BERT. They're then fine-tuned on a dataset of (query, relevant_doc) pairs using a special loss function that encourages the model to produce sparse activations.
SPLADE模型是双编码器变压器模型,从像BERT这样的掩码语言模型初始化。然后使用特殊的损失函数在(查询,相关文档)对数据集上进行微调,该损失函数鼓励模型产生稀疏激活。
The key innovation is in how SPLADE generates these sparse vectors. Rather than producing dense vectors and then sparsifying them, SPLADE directly produces sparse vectors by applying a ReLU activation function to the transformer output and then using the resulting values as weights for the vocabulary terms.
关键创新在于SPLADE如何生成这些稀疏向量。SPLADE不是产生密集向量然后将其稀疏化,而是通过在变压器输出上应用ReLU激活函数,然后将生成的值用作词汇术语的权重,直接产生稀疏向量。
This approach has several advantages:
这种方法有几个优势:
-
Interpretability: Each non-zero dimension in the sparse vector corresponds to an actual term in the vocabulary, making it easy to understand why a document was retrieved.
可解释性:稀疏向量中的每个非零维度对应词汇表中的一个实际术语,使得容易理解为什么检索到某个文档。
-
Efficiency: Sparse vectors can be efficiently indexed and searched using traditional inverted indexes, without requiring specialized ANN techniques.
效率:稀疏向量可以使用传统的倒排索引高效索引和搜索,而无需专门的ANN技术。
-
Semantic Understanding: By leveraging the transformer architecture, SPLADE can capture semantic relationships between terms, leading to better retrieval performance than purely lexical models.
语义理解:通过利用变压器架构,SPLADE可以捕捉术语之间的语义关系,从而比纯词汇模型有更好的检索性能。
Benefits of SPLADE | SPLADE的优势
SPLADE offers several key benefits over traditional sparse and dense retrieval methods:
SPLADE相比传统的稀疏和密集检索方法提供了几个关键优势:
-
Improved Performance: SPLADE can outperform both traditional sparse methods (like BM25) and dense methods (like BERT embeddings) on many retrieval tasks, especially when training data is limited.
性能提升:在许多检索任务中,SPLADE可以超越传统的稀疏方法(如BM25)和密集方法(如BERT嵌入),特别是在训练数据有限时。
-
Reduced Engineering Complexity: Unlike two-stage systems, SPLADE provides a single-stage retrieval solution that's simpler to implement and maintain.
降低工程复杂性:与两阶段系统不同,SPLADE提供了一个更简单实现和维护的单阶段检索解决方案。
-
Better Handling of Vocabulary Mismatch: By learning term expansions, SPLADE can bridge the gap between query terms and document terms, even when they don't match exactly.
更好地处理词汇不匹配:通过学习术语扩展,SPLADE可以在查询术语和文档术语之间架起桥梁,即使它们不完全匹配。
-
Compatibility with Existing Infrastructure: SPLADE's sparse vectors can be easily integrated into existing search systems that already support sparse retrieval.
与现有基础设施兼容:SPLADE的稀疏向量可以轻松集成到已经支持稀疏检索的现有搜索系统中。
Conclusion | 结论
SPLADE represents an important advancement in information retrieval by successfully combining the semantic understanding capabilities of transformer models with the efficiency and interpretability of sparse representations. This approach addresses some of the key challenges in modern search systems, where there is often a trade-off between effectiveness and efficiency.
SPLADE通过成功结合变压器模型的语义理解能力和稀疏表示的效率和可解释性,代表了信息检索的重要进展。这种方法解决了现代搜索系统中的一些关键挑战,在这些系统中有效性与效率之间往往存在权衡。
As search systems continue to evolve, models like SPLADE that bridge the gap between lexical and semantic approaches will likely play an increasingly important role in providing both effective and efficient retrieval capabilities.
随着搜索系统的不断发展,像SPLADE这样弥合词汇和语义方法之间差距的模型将在提供有效和高效的检索能力方面发挥越来越重要的作用。
For practitioners looking to implement advanced retrieval systems, SPLADE offers a compelling middle ground between traditional sparse methods and dense embedding approaches, with the added benefit of being learnable and adaptable to specific domains.
对于希望实现高级检索系统的从业者来说,SPLADE在传统稀疏方法和密集嵌入方法之间提供了一个引人注目的中间地带,额外的好处是可学习且能适应特定领域。
Pinecone: Chunking Strategies for LLM Applications | Pinecone:LLM 应用的分块策略
Learn about chunking strategies for LLM applications, including fixed-size chunking, content-aware chunking, semantic chunking, and contextual chunking. 了解 LLM 应用的分块策略,包括固定大小分块、内容感知分块、语义分块和上下文分块。
[技术] SPLADE双编码器模型
了解SPLADE模型如何结合稀疏表示和BERT的语义理解能力来实现高效的信息检索。Understanding how the SPLADE model combines sparse representations with BERT's semantic understanding for efficient information retrieval.