[向量检索] 向量搜索详解
向量搜索是现代信息检索系统的核心技术,特别是在AI原生应用中。Vector search is a core technology in modern information retrieval systems, especially in AI-native applications.
向量搜索详解 | Vector Search Explained
向量搜索从根本上改变了我们在现代开发中处理信息检索的方式。它基于称为向量嵌入的数据的数值表示进行操作,这些表示在向量空间中捕获语义含义。向量搜索可以在不需要精确文本匹配的情况下识别相关对象,使其在现代信息检索系统中变得越来越重要,特别是在传统搜索系统不足的AI原生应用中。
Vector search has fundamentally shifted how we approach information retrieval in modern development. It operates on numerical representations of data called vector embeddings, which capture the semantic meaning in a vector space. Vector search can identify related objects without requiring exact text matches, making it increasingly important for modern information retrieval systems, particularly in AI-native applications where traditional search systems fall short.
什么是向量搜索?| What is vector search?
向量搜索是一种通过比较向量表示来在大型数据集中查找和检索相似项目的技 术,这些向量表示是其特征的数值编码。与依赖精确匹配的传统搜索不同,向量搜索基于含义或上下文寻找相似性。它用于图像检索、推荐系统和搜索引擎等应用中。
Vector search is a technique for finding and retrieving similar items in large datasets by comparing their vector representations, which are numerical encodings of their features. Unlike traditional search that relies on exact matches, vector search looks for similarity based on meaning or context. It's used in applications like image retrieval, recommendation systems, and search engines.
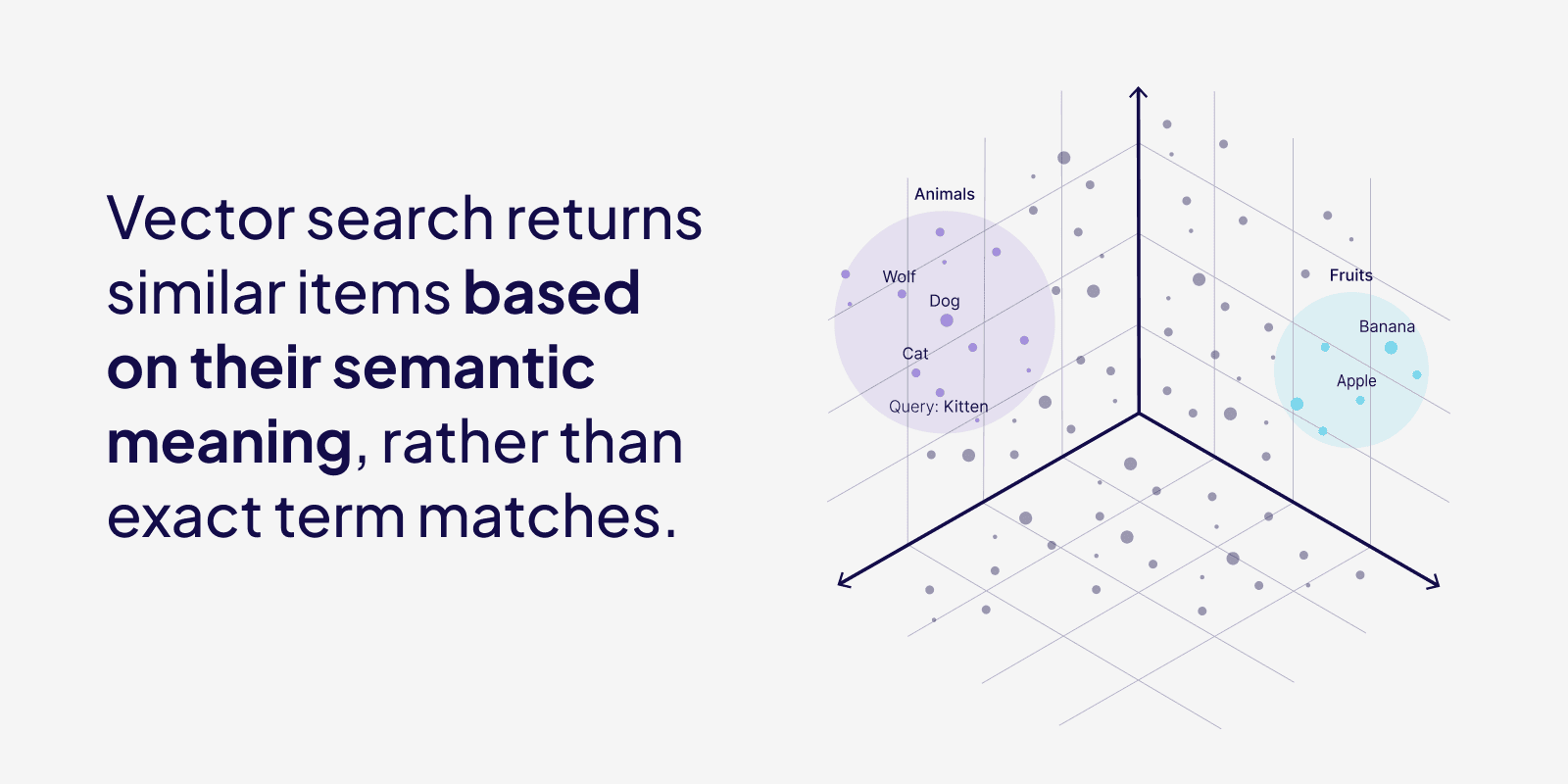
向量搜索是如何工作的?| How does vector search work?
向量搜索通过将数据和查询转换为向量嵌入来工作。向量嵌入是由语言模型生成的,这些模型学会在数值表示中捕获数据的含义和上下文。
Vector search works by converting data and queries into vector embeddings. Vector embeddings are generated by language models that learn to capture the meaning and context of data within numerical representations.
在条目/导入时(或数据对象发生重大变化时),每个数据对象和查询都使用嵌入模型转换为数值向量表示。数据集中的每个数据对象都会获得一个向量,在搜索时将其与查询向量进行比较。
At the time of entry/import (or any significant changes to data objects), every data object, and the query, are converted into numerical vector representations using embedding models. Every data object in a dataset gets a vector, and this is compared to the query vector at search time.
简而言之,向量嵌入是一个数字数组,可以用作高维空间中的坐标。虽然很难想象超过三维空间(x, y, z)中的坐标,但我们仍然可以使用向量来计算向量之间的距离,这可以用来表示对象之间的相似性。有许多不同的距离度量,如余弦相似度和欧几里得距离(L2距离)。
In a nutshell, vector embeddings are an array of numbers, which can be used as coordinates in a high-dimensional space. Although it is hard to imagine coordinates in more than 3-dimensional space (x, y, z), we can still use the vectors to compute the distance between vectors, which can be used to indicate similarity between objects. There are many different distance metrics, like cosine similarity and Euclidean distance (L2 distance).
每当我们运行查询(如:"柏林最高的建筑是什么?")时,向量搜索系统会将其转换为"查询"向量。向量数据库的任务是使用距离度量和搜索算法识别和检索与查询向量最接近的向量列表。
Whenever we run a query (like: "What is the tallest building in Berlin?"), a vector search system will convert it to a "query" vector. The task of a vector database is to identify and retrieve a list of vectors that are closest to the vector of your query, using a distance metric and a search algorithm.
这有点像滚球游戏——其中小标记(目标球)是我们查询向量的位置,球是我们的数据向量——我们需要找到离标记最近的球。
This is a bit like a game of boules – where the small marker (jack) is the location of our query vector, and the balls (boules) are our data vectors – and we need to find the boules that are nearest to the marker.
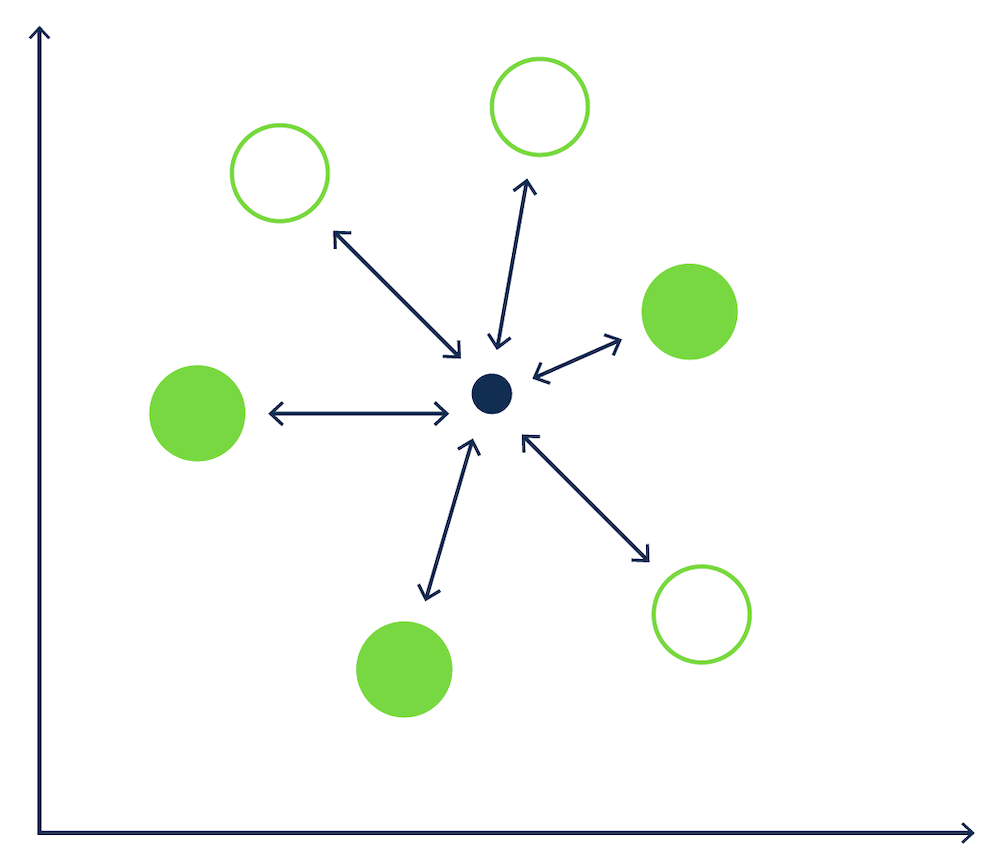
[kNN搜索在滚球游戏中的示意图 | kNN search in a game of Boules]
k最近邻(kNN)算法是搜索算法的一个例子,它通过计算数据库中每个数据向量与查询向量的相似度得分来返回k个最近的向量。在我们的滚球例子中,有6个球,kNN算法会测量目标球与地面上6个球之间的距离。这将导致6次单独的计算。
An example of a search algorithm is a k-nearest neighbors (kNN) algorithm, which returns the k nearest vectors, by calculating a similarity score for every data vector in the database to the query vector. In our boules example, with 6 boules, the kNN algorithm would measure the distance between the jack and each of the 6 boules on the ground. This would result in 6 separate calculations.
如何在Python中实现向量搜索(从头开始)| How to implement Vector Search (from scratch) in Python
我们可以用几行Python代码从头开始实现一个简单的向量搜索解决方案。
We can implement a simple vector search solution from scratch with just a few lines of code in Python.
让我们首先安装OpenAI python包来为我们的文本生成向量嵌入,以及numpy来进行相似度计算。
Let's start by installing the OpenAI python package to generate vector embeddings for our text, and numpy to do our similarity calculations.
pip install openai
pip install numpy然后我们可以导入所有依赖项,设置我们的OPENAI_API_KEY,并定义我们的句子列表。
Then we can import all our dependencies, set our OPENAI_API_KEY, and define our list of sentences.
from openai import OpenAI
from dotenv import load_dotenv
import os
import numpy as np
load_dotenv()
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
)
sentences = [
"Best pizza places nearby.",
"Popular breakfast spots in New York.",
"Top-rated seafood restaurants in Miami.",
"Cheap hotels near the beach.",
"Recipes for quick pasta dishes.",
]我们可以使用OpenAI为每个句子生成向量嵌入,并将这些存储在新字典中。
We can use OpenAI to generate vector embeddings for every sentence, and store these in a new dictionary.
def get_embedding(text, model="text-embedding-3-small"):
embedding = client.embeddings.create(input=[text], model=model).data[0].embedding
return embedding
sentence_vectors = {}
for sentence in sentences:
embedding = get_embedding(sentence)
sentence_vectors[sentence] = embedding要计算查询和每个句子之间的相似度得分,我们可以使用余弦相似度评分方法。
To calculate the similarity score between the query and each sentence, we can use cosine similarity scoring method.
def calculate_cosine_similarity(query_vector, vector):
return np.dot(query_vector, vector) / (np.linalg.norm(query_vector) * np.linalg.norm(vector))最后,这个函数将获取我们的查询,将其转换为向量,并计算每个查询向量和文档向量之间的相似度得分。然后,它将根据相关性对结果进行排序,并返回得分最高的两个句子。
Finally, this function will take our query, convert it to a vector, and calculate the similarity score between every query vector and document vector. Then, it will order the results based on relevance, and return the top two scored sentences.
def get_top_n_similar(query_sentence, n=2):
query_embedding = get_embedding(query_sentence)
similarities = {sentence: calculate_cosine_similarity(query_embedding, sentence_vectors[sentence]) for sentence in sentences}
sorted_similarities = dict(sorted(similarities.items(), key=lambda x: x[1], reverse=True))
top_matches = list(sorted_similarities.items())[:n]
for sentence, score in top_matches:
print(f"Similarity: {score:.4f} - {sentence}")您可以看到,即使查询和第一个返回的句子没有所有共同的单词,它仍然得分很高,因为_含义_非常相似。
You can see that even though the query and the first returned sentence don't have all the words in common, it still scores as a high match because the meaning is very similar.
query_sentence = "Find the best pizza restaurant close to me."
get_top_n_similar(query_sentence, n=2)Similarity: 0.7056 - Best pizza places nearby.
Similarity: 0.3585 - Top-rated seafood restaurants in Miami.尽管这种方法能够基于文本向量给我们相似的项目,但它相当低效。手动计算大型数据集中每个向量的余弦相似度会很快变得计算昂贵。此外,没有索引机制,所有向量都以原始形式存储,需要高内存消耗并减慢搜索速度。最后,仅将向量和文本对象存储在字典中意味着我们缺乏结构化数据库功能。
Although this method is able to give us similar items based on text vectors, it's pretty inefficient. Manually computing cosine similarity over every vector in a large dataset can become computationally expensive fast. Also, without an indexing mechanism, all the vectors are stored in their raw form, requiring high memory consumption and slowing down search speeds. And finally, just storing the vectors and text objects in a dictionary means we lack structured database features.
为了解决所有这些问题,我们可以使用向量数据库来存储和搜索我们的向量。
To fix all these problems, we can use a vector database to store and search through our vectors.
向量数据库中的向量搜索 | Vector search in vector databases
使用向量数据库的向量搜索,也称为语义搜索,能够快速高效地处理大量非结构化数据(想想段落而不是电子表格),并基于语义相似性而不是精确匹配在搜索和推荐系统中提供相关结果。这可以让您在数百万个文档中进行高级搜索,例如,包含超过2800万个段落的维基百科数据集。
Vector search, also called semantic search, using a vector database is able to handle large amounts of unstructured data (think paragraphs instead of spreadsheets) quickly and efficiently, and provides relevant results in search and recommendation systems based on semantic similarity rather than exact matches. This can allow you to do advanced search through millions of documents, for example, a Wikipedia dataset with over 28 million paragraphs.
如果我们查询:"欧洲的城市规划",向量数据库(如Weaviate)会响应一系列关于该主题的文章,如"被设计为首都的城市"。
If we query for articles related to: "urban planning in Europe", the vector database (like Weaviate) responds with a series of articles about the topic, such as "The cities designed to be capitals".
在巨大的非结构化数据存储库中找到正确答案并不是向量数据库最令人印象深刻的部分(我的意思是,这非常令人印象深刻),而是这一切发生的🚀速度。为了找到与我们的语义搜索查询最相关的答案,在包含2800万个段落的数据集中只需要几毫秒。这在处理大量数据时非常重要,如推荐引擎或大型文档数据集。
Finding the correct answer in a gigantic repository of unstructured data is not the most impressive part of vector databases (I mean, it is very impressive), but it is the 🚀 speed at which it all happens. To find the most relevant answer to our semantic search query, it only takes milliseconds in a dataset containing 28 million paragraphs. This is super important when dealing with massive amounts of data, like in recommendation engines or large document datasets.
在解释之后,随之而来的不可避免的问题总是:为什么这如此难以置信地快?
The inevitable question that follows up this explanation is always: Why is this so incredibly fast?
近似最近邻(ANN)| Approximate nearest neighbors (ANN)
大多数向量数据库不逐个比较向量,而是使用近似最近邻(ANN)算法,这些算法在准确性上做了一些权衡(因此名称中的A)以获得巨大的速度提升。
Instead of comparing vectors one by one, most vector databases use Approximate Nearest Neighbor (ANN) algorithms, which trade off a bit of accuracy (hence the A in the name) for a huge gain in speed.
ANN算法可能不会返回真正的k个最近向量,但它们非常高效。ANN算法在非常大规模的数据集上保持良好的性能(次线性时间,例如(多项式)对数复杂度)。
ANN algorithms may not return the true k nearest vectors, but they are very efficient. ANN algorithms maintain good performance (sublinear time, e.g. (poly)logarithmic complexity) on very large-scale datasets.
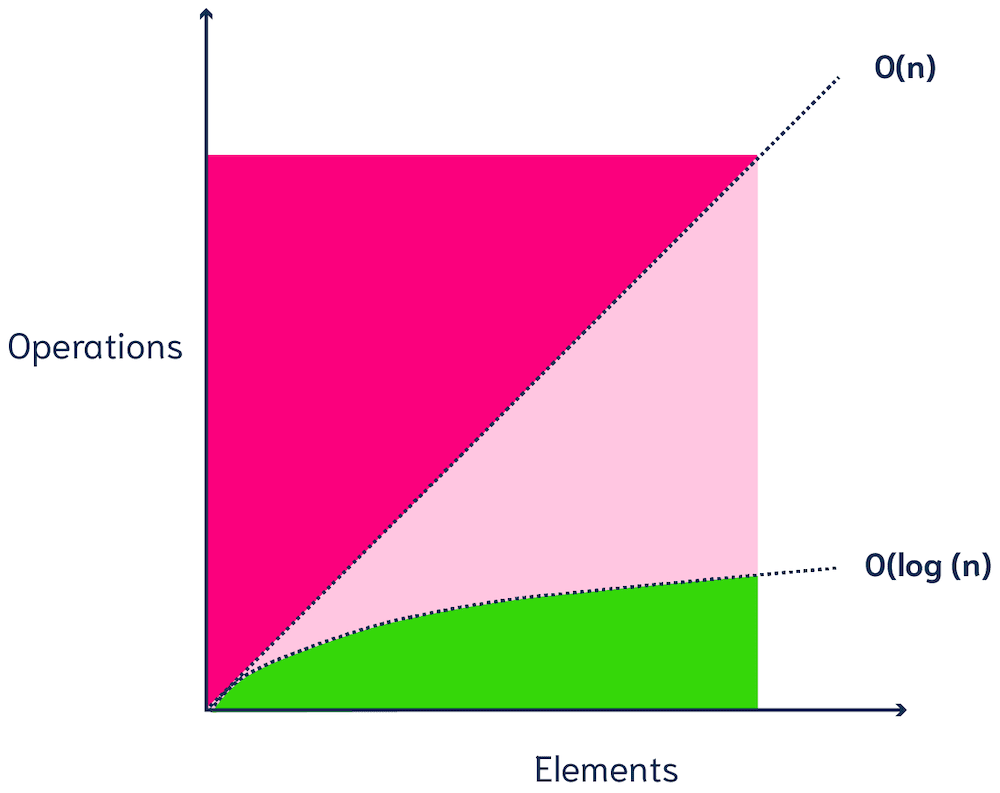
[O(n)和O(log n)复杂度 | O(n) and O(log n) complexity]
请注意,大多数向量数据库允许您配置ANN算法的行为方式。这让您能够在召回率权衡(结果中真正前k个最近邻居的分数)、延迟、吞吐量(每秒查询数)和导入时间之间找到正确的平衡。
Note that most vector databases allow you to configure how your ANN algorithm should behave. This lets you find the right balance between the recall tradeoff (the fraction of results that are the true top-k nearest neighbors), latency, throughput (queries per second) and import time.
ANN算法示例 | Examples of ANN algorithms
ANN方法的示例包括:
Examples of ANN methods are:
trees – e.g. ANNOY (Figure 3) proximity graphs - e.g. HNSW (Figure 4) clustering - e.g. FAISS hashing - e.g. LSH
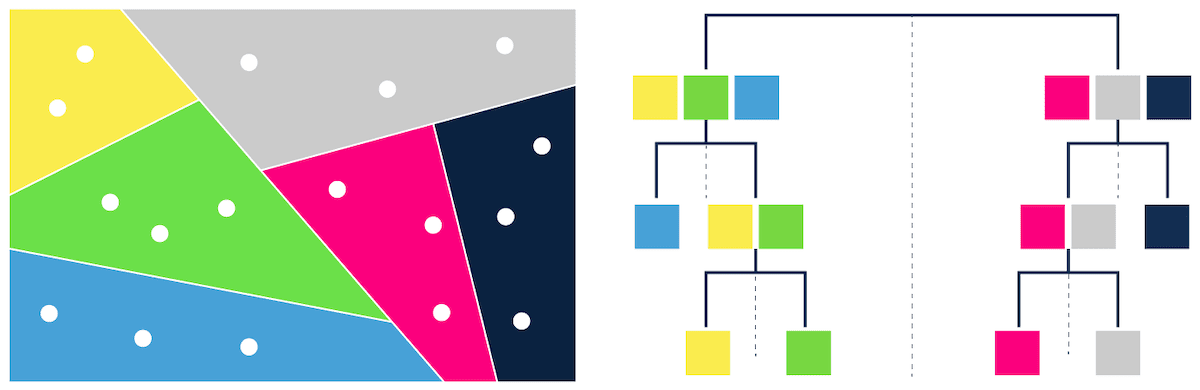
[基于树的ANN搜索 | Tree-based ANN search]
哪种算法效果最好取决于您的项目。性能可以通过延迟、吞吐量(每秒查询数)、构建时间和准确性(召回率)来衡量。这四个组件通常存在权衡,因此取决于用例,哪种方法效果最好。
Which algorithm works best depends on your project. Performance can be measured in terms of latency, throughput (queries per second), build time, and accuracy (recall). These four components often have a tradeoff, so it depends on the use case which method works best.
因此,虽然ANN并不是某种总能找到数据集中真正k个最近邻居的神奇方法,但它可以找到真正k个邻居的相当好的近似。而且它可以在一小部分时间内做到这一点!
So, while ANN is not some magic method that will always find the true k nearest neighbors in a dataset, it can find a pretty good approximation of the true k neighbors. And it can do this in a fraction of the time!
Weaviate中的HNSW | HNSW in Weaviate
Weaviate是使用ANN算法提供超快查询的向量数据库的一个很好的例子。Weaviate使用的ANN算法是分层可导航小世界图(HNSW)的自定义实现。
Weaviate is a great example of a vector database that uses ANN algorithms to offer ultra-fast queries. The ANN algorithm that Weaviate uses is a custom implementation of Hierarchical Navigable Small World graphs (HNSW).
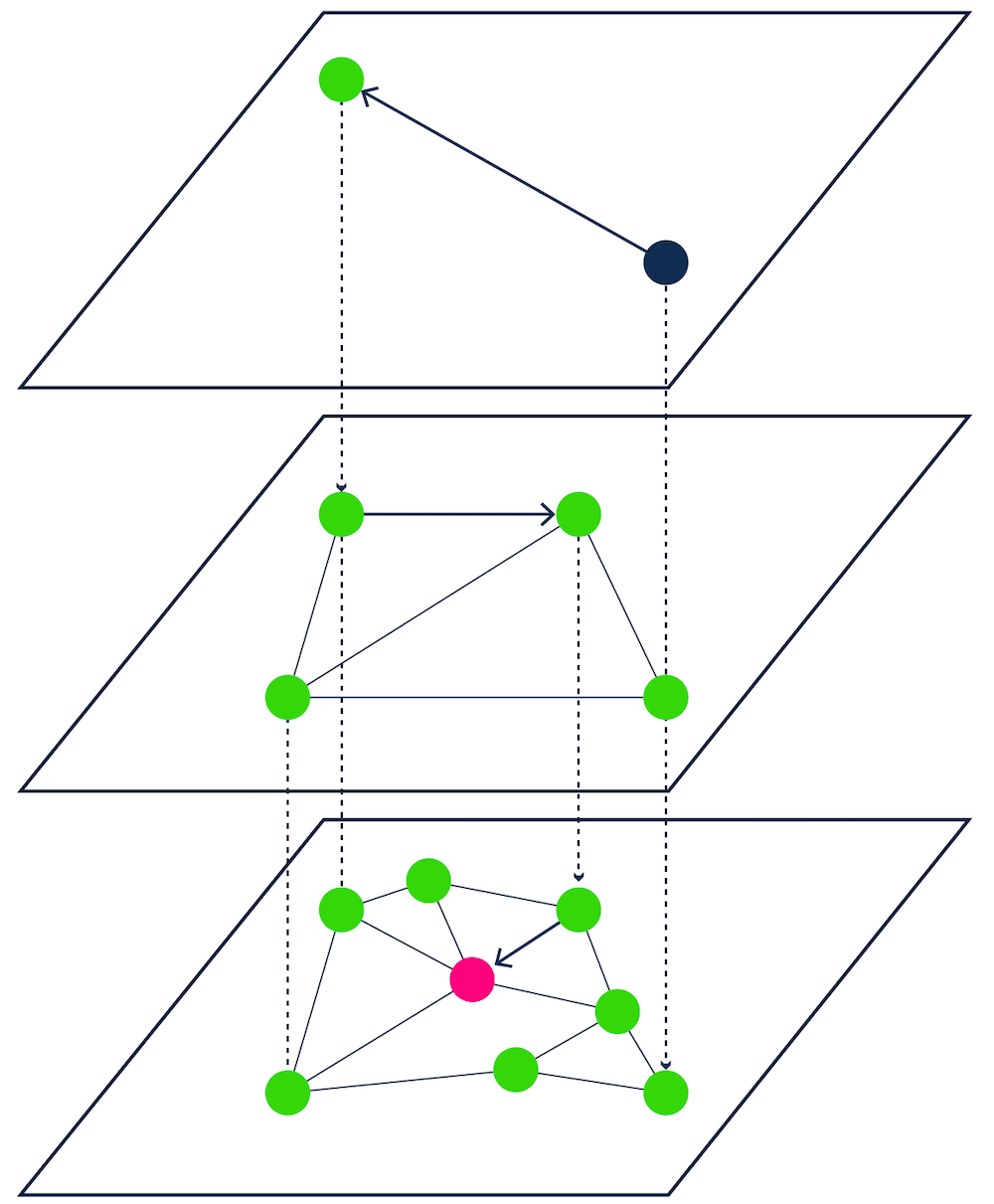
[HNSW - 基于邻近图的ANN搜索 | HNSW - Proximity graph-based ANN search]
HNSW通过将向量组织成分层的多层图结构来工作,这允许在搜索期间快速导航数据集。HNSW的结构在上层平衡了较长距离以实现快速搜索,在下层平衡了较短距离以实现精确搜索。
HNSW works by organizing vectors into a hierarchical, multi-layered graph structure, which allows for fast navigation through the dataset during search. The structure of HNSW balances longer distances for faster search in upper layers and shorter distances for accurate search in lower layers.
在Weaviate的实现中,HNSW得到了增强,支持完整的CRUD操作,并允许实时查询、更新和删除,具有增量磁盘写入以实现崩溃恢复和异步清理过程以保持索引新鲜度等功能。
In Weaviate's implementation, HNSW is enhanced to support full CRUD operations and allows for real-time querying, updates, and deletions, with features like incremental disk writes for crash recovery and asynchronous cleanup processes for maintaining index freshness.
查看Weaviate ANN基准测试以了解HNSW在现实大规模数据集上的表现。您可以使用它来比较召回率、QPS、延迟和导入时间之间的权衡。
Check out Weaviate ANN benchmarks to see how HNSW performed on realistic large-scale datasets. You can use it to compare the tradeoffs between recall, QPS, latency, and import time.
您会发现有趣的是,Weaviate可以保持非常高的召回率(>95%),同时保持高吞吐量和低延迟(都在毫秒级)。这正是您快速但可靠的向量搜索所需要的!
You will find it interesting to see that Weaviate can maintain very high recall rates (>95%), whilst keeping high throughput and low latency (both in milliseconds). That is exactly what you need for fast, but reliable vector search!
如果您对为自己的数据集进行基准测试感兴趣,请查看这个网络研讨会。
If you're interested in benchmarking for your own dataset, check out this webinar.
ANN vs. KNN
kNN,或k最近邻(kNN)算法,与ANN不同,因为它计算数据库中_每个数据向量_与查询向量相比的相似度得分,就像我们上面从头开始的向量搜索示例一样。
kNN, or k-nearest neighbors (kNN) algorithm, differs from ANN because it calculates a similarity score for every data vector in the database compared to the query vector, much like our vector search from scratch example above.
在只有两个维度的情况下,将查询向量与10、100或1000个数据向量进行比较是一项容易的工作。但当然,在现实世界中,我们更可能处理数百万(如维基百科数据集)甚至数十亿个数据项。此外,大多数嵌入模型在语义搜索中使用的维度数达到数百或数千维!
Comparing a query vector with 10, 100, or 1000 data vectors in just two dimensions is an easy job. But of course, in the real world, we are more likely to deal with millions (like in the Wikipedia dataset) or even billions of data items. In addition, the number of dimensions that most embedding models use in semantic search goes up to hundreds or thousands of dimensions!
kNN搜索的_暴力_计算非常昂贵——根据数据库的大小,单个查询可能需要几秒钟甚至几小时(哎呀😅)。如果您将一个300维的向量与1000万个向量进行比较,搜索系统需要进行300 x 1000万 = 30亿次计算!所需的计算次数随数据点数量线性增加(O(n))。
The brute force of a kNN search is computationally very expensive - and depending on the size of your database, a single query could take anything from several seconds to even hours (yikes 😅). If you compare a vector with 300 dimensions with 10M vectors, the search system would need to do 300 x 10M = 3B computations! The number of required calculations increases linearly with the number of data points (O(n)).
总之,kNN搜索不能很好地扩展,在生产环境中很难想象将其用于大型数据集。
In summary, kNN search doesn't scale well, and it is hard to imagine using it with a large dataset in production.
向量搜索的类型 | Types of vector search
向量搜索不仅限于文本,甚至不限于单一语言的文本。任何东西都可以通过正确的嵌入模型转换为向量,无论是图像、音频、视频还是多语言文档。这意味着我们可以开发多模态或多语言的语义搜索系统,能够处理各种数据格式、语言或搜索类型。
Vector search is not just limited to text, or even text in a single language. Anything can be converted into a vector with the right embedding model, whether it's images, audio, video, or multi-lingual documents. This means we can develop multi-modal or multi-lingual semantic search systems that can handle a variety of data formats, languages, or search types.
图像向量搜索 | Image Vector Search
图像向量搜索将图像转换为向量表示,以实现基于视觉相似性的图像间搜索。向量嵌入编码颜色、形状和纹理等特征,使您能够基于视觉相似性而不是仅基于元数据搜索图像。这种搜索经常用于电子商务中寻找视觉上相似的产品,或在内容审核中使用。
Image vector search converts images into vector representations to enable similarity searches between images. The vector embeddings encode features like colors, shapes, and textures so that you can search for images based on visual similarity rather than metadata alone. This type of search is frequently used in fields like e-commerce for finding visually similar products, or in content moderation.
音频向量搜索 | Audio Vector Search
音频向量搜索将音频文件转换为向量,以基于声音特征(如音调、节奏或旋律)进行相似性搜索。这用于音乐发现平台、音效库和语音识别系统等应用中。
Audio vector search transforms audio files into vectors to power similarity search based on sound characteristics, such as tone, rhythm, or melody. This is used in applications like music discovery platforms, sound effect libraries, and voice recognition systems.
视频向量搜索 | Video Vector Search
视频向量搜索通过采样帧或分析场景特征等方法将视频转换为向量嵌入,以基于视觉和有时音频相似性进行搜索。这种方法在内容库、监控和媒体数据库等应用中很受欢迎。
Video vector search converts videos into vector embeddings through methods like sampling frames or analyzing scene features for search based on visual and sometimes audio similarity. This method is popular in applications like content libraries, surveillance, and media databases.
多模态向量搜索 | Multimodal Vector Search
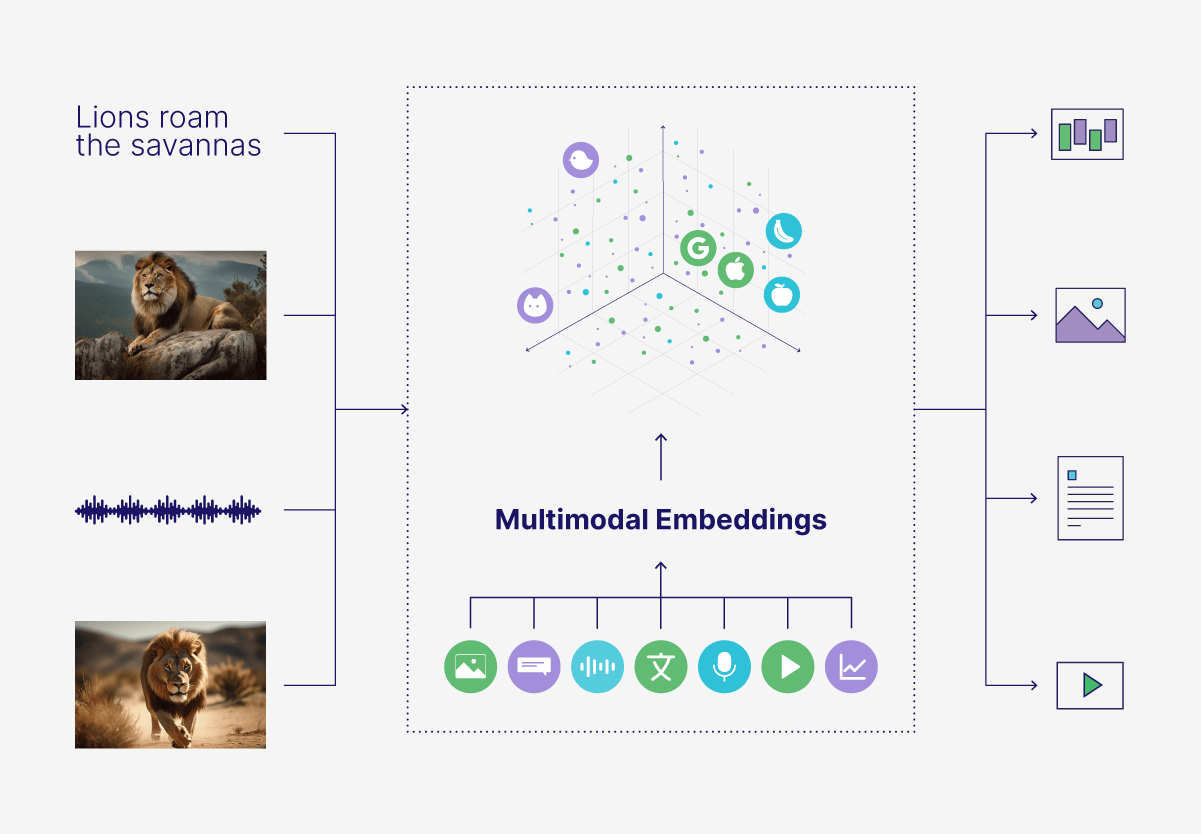
多模态向量搜索将不同类型的数据(如文本、图像和音频)组合在同一个向量空间中进行跨类型比较。例如,您可以仅基于描述找到与文本查询最相似的图像或音频,如仅基于描述检索狮子图像或狮子咆哮声。这可以用于电子商务、数字资产管理和社会媒体平台等应用中搜索各种媒体格式。
Multimodal vector search combines different data types—like text, images, and audio—in the same vector space for cross-type comparisons. For example, you could find images or audio most similar to a text query, like retrieving images of a lion or a lion's roar based on a description alone. This can be used in applications to search across various media formats, like e-commerce, digital asset management, and social media platforms.
多语言向量搜索 | Multilingual Vector Search
多语言向量搜索可以通过将文本嵌入到同一个向量空间中来比较不同语言的文本。例如,英文查询可以检索描述相似概念的其他语言(如法语或中文)的文档、标题或内容。这些跨语言搜索可以为全球电子商务、多语言客户支持和国际内容发现等应用提供支持。
Multilingual vector search can compare text across languages by embedding it into the same vector space. For instance, a query in English could retrieve documents, captions, or content in other languages, such as French or Chinese, describing similar concepts. These cross-lingual searches can power applications like global e-commerce, multilingual customer support, and international content discovery.
混合搜索 | Hybrid Search
混合搜索将多种搜索类型(通常是向量搜索和关键字搜索)组合在一个系统中。通过将传统关键字搜索与语义搜索相结合,我们得到了两全其美的效果:语义上下文+特定关键字。语义搜索在理解文档和查询的一般含义方面效果很好,但它不会优先考虑确切的匹配,如名称、行业特定术语或罕见词汇,这在许多类型的应用中都很有帮助。但没有语义搜索(只有关键字),结果可能会错过相关的语义信息和关于所需主题的上下文。结合这两种方法可以提高搜索结果的准确性和相关性。
Hybrid search combines multiple search types, usually vector search and keyword search, in a single system. By combining traditional keyword search with semantic search, we get the best of both worlds: semantic context + specific keywords. Semantic search works great for understanding the general meaning of the documents and query, but it doesn't prioritize exact matches such as names, industry-specific jargon, or rare words, which can be helpful in many types of applications. But without semantic search (only keyword), the results can miss relevant semantic information and context about the desired topic. Combining these two methods can improve both the accuracy and relevance of search results.
向量搜索的优势 | Benefits of vector search
传统的基于关键字的搜索系统只能匹配文本中的_确切术语或短语_,或关键词。相比之下,向量搜索基于其底层上下文或含义返回相似项目,并适用于各种数据类型,包括文本、图像、音频或视频。例如,搜索"健康零食"可能会返回语义相关的术语,如"营养食品"或"低热量零食",或者在多模态系统的情况下,返回燕麦棒或水果的图片。
Traditional keyword-based search systems can only match exact terms or phrases, or key words, in text. In contrast, vector search returns similar items based on their underlying context or meaning, and works with a variety of data types, including text, images, audio or video. For example, a search for "healthy snacks" might return semantically related terms like "nutritious food" or "low-calorie treats", or in the case of a multimodal system, pictures of granola bars or fruit.
这就是为什么向量搜索通常也被称为语义搜索。它实现了更"类人"的搜索体验,允许用户在不需要查询中使用确切词汇的情况下找到相关对象。
This is why vector search is often also called semantic search. It enables a more "human-like" search experience, allowing users to find related objects without needing to have the exact right words in their query.
向量搜索的应用场景 | Vector search use cases
向量搜索可以为各种不同的应用和用例提供支持,从高级搜索系统到推荐系统再到聊天机器人。
Vector search can power a variety of different applications and use cases, from advanced search systems, to recommendation systems, to chatbots.
搜索系统 | Search Systems
向量搜索可以应用于各种不同的搜索系统,从十亿级的电子商务应用到多模态和多语言搜索应用,再到大型企业的内部文档搜索。例如,在电子商务中,语义搜索可以根据客户意图推荐产品,即使他们的搜索查询中没有确切的关键词。通过正确的嵌入模型选择,您可以创建多语言应用,如WeaLingo,或多模态搜索应用。向量搜索还可以加快企业搜索等用例的结果时间,因为ANN算法允许在大量非结构化文档中快速检索。
Vector search can be applied to a wide range of different search systems, from billion-scale e-commerce applications to multi-modal and multi-lingual search apps to internal document search in large enterprises. For example, in e-commerce, semantic search can recommend products based on customer intent, even if they don't have the exact keywords in their search query. With the right embedding model selection, you could create multilingual, like WeaLingo, or multimodal search apps out of the box. Vector search can also speed up result time for use cases like enterprise search, because the ANN algorithms allow for such fast retrieval speeds over large numbers of unstructured documents.
推荐系统 | Recommendation Systems
向量搜索可用于推荐系统中,通过查找具有相似向量表示的项目来根据用户偏好推荐类似的产品、电影或内容,即使它们没有共享的元数据或标签。这在社交媒体应用、新闻网站或电子商务商店中被广泛使用。
Vector search can be used in recommendation systems to recommend similar products, movies, or content based on user preferences by finding items with similar vector representations, even without shared metadata or tags. This is widely used in social media apps, news sites, or e-commerce stores.
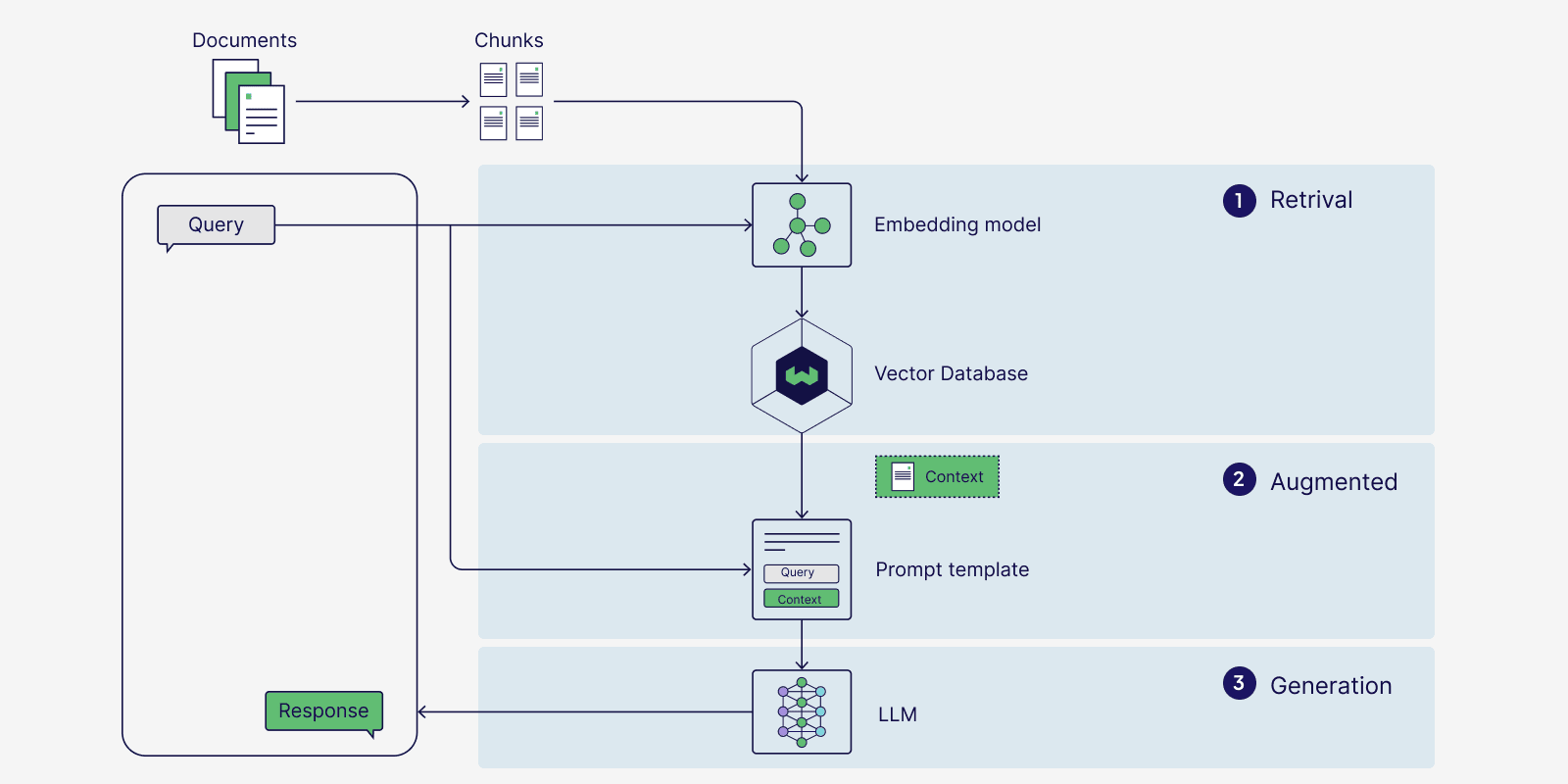
检索增强生成(RAG)| Retrieval Augmented Generation (RAG)
检索增强生成,或RAG,是向量搜索在聊天机器人或问答系统等应用中的热门用例。RAG只是向量搜索的一个额外步骤——向量数据库返回的相似结果被提供给大型语言模型(LLM)以生成与用户查询上下文相关的响应。RAG有助于最小化模型幻觉,提高响应准确性,并允许生成模型访问专门知识以回答复杂的、数据驱动的查询。
Retrieval Augmented Generation, or RAG, is a popular use case of vector search used in applications like chatbots or question-answering systems. RAG is just vector search with an extra added step - the similar results returned by the vector database are given to a large language model (LLM) to generate a contextually relevant response to the user's query. RAG helps minimize model hallucinations, increase accuracy of responses, and allows generative models to access specialized knowledge to answer complex, data-driven queries.
语义搜索对于RAG应用来说很棒,因为它速度快,并且能够基于含义而不是精确匹配来搜索文档。
Semantic search is great for RAG applications because of its speed and ability to search for documents based on meaning, rather than exact matches.
向量搜索解决方案 | Vector search solutions
有几种不同的方法可以在应用中启用向量搜索:
There are a few different ways to enable vector search in applications:
向量索引库如FAISS、Annoy和ScaNN针对内存中的相似性搜索进行了优化,只存储向量,而不是它们来源的数据对象。它们的索引通常是不可变的,这意味着它们不能动态更新而无需重建。此外,向量库通常需要在查询之前导入所有数据,这可能会限制它们在动态或不断更新环境中的灵活性。这些库适用于涉及静态数据且不需要完整CRUD操作或持久性功能的应用。
Vector indexing libraries such as FAISS, Annoy, and ScaNN, are optimized for in-memory similarity searches and only store vectors, not the data objects they originate from. Their indexes are generally immutable, meaning they can't be updated dynamically without rebuilding. Additionally, vector libraries often require all data to be imported before querying, which can limit their flexibility in dynamic or constantly updating environments. These libraries are good for applications that involve static data and do not need full CRUD operations or persistence capabilities.
支持向量的数据库扩展了传统数据库的向量搜索功能,允许企业在利用现有数据库功能的同时整合语义搜索。这些解决方案在可靠性和大规模速度方面通常存在困难。
Vector-capable databases extend traditional databases with vector search capabilities, allowing businesses to incorporate semantic search while leveraging existing database features. These solutions generally struggle with reliability and speed at scale.
向量数据库(如Weaviate)为语义搜索用例提供了全面的解决方案,支持向量索引,还管理数据持久性、扩展和与AI生态系统的集成。它们为各种用例提供了灵活的解决方案,从大规模AI应用到刚入门的用户。
Vector databases (such as Weaviate) offer a comprehensive solution to semantic search use cases, supporting vector indexing and also managing data persistence, scaling, and integration with the AI ecosystem. They have flexible solutions for a variety of use cases, from AI applications at scale to users who are just getting started.
向量搜索引擎这个术语经常与向量数据库互换使用,但从技术上讲它们是不同的:向量搜索引擎只关注检索层,而向量数据库包括存储、数据管理和集群等附加功能。
A vector search engine is often used interchangeably with a vector database, but they are technically different: a vector search engine focuses only on the retrieval layer, while a vector database includes additional features like storage, data management, and clustering.
向量搜索常见问题 | Vector search FAQs
语义搜索vs向量搜索 | Semantic search vs Vector search
在正式定义方面,向量搜索只是将向量嵌入或向量排列到向量索引中以执行相似性搜索的过程,而语义搜索在向量搜索的基本定义基础上构建,以返回基于文本含义而不是确切术语的更相关结果。但在实践中,向量搜索和语义搜索经常互换使用。
In terms of formal definitions, vector search is just the process of arranging vector embeddings, or vectors, into a vector index to perform similarity searches, while semantic search builds on the basic definition of vector search to return more relevant results based on the meaning of text rather than exact terms. In practice, though, vector search and semantic search are often used interchangeably.
向量搜索vs关键字搜索 | Vector search vs Keyword search
向量搜索基于数据的语义含义查找相似项目,而关键字搜索依赖于确切的单词匹配或短语出现。向量搜索可以处理非结构化、多模态数据(如文本、图像或音频)并查找相关概念,而关键字搜索更适合结构化文本数据,其中确切措辞很重要。
Vector search finds similar items based on the semantic meaning of the data, while keyword search relies on exact word matches or phrase occurrences. Vector search can handle unstructured, multimodal data (like text, images or audio) and find related concepts, while keyword search is more suited for structured text data where exact phrasing is important.
如何大规模进行向量搜索?| How is vector search conducted at scale?
向量数据库使用近似最近邻(ANN)算法来加快大规模数据集的搜索时间。通过ANN算法,向量搜索可以在几毫秒内返回与查询相似的项目,即使是从数十亿个对象中。
Vector databases use Approximate Nearest Neighbor (ANN) algorithms to speed up search time for large datasets. With ANN algorithms, vector search can return similar items to the query within a few milliseconds, even out of billions of objects.
总结 | Summary
快速回顾:
A quick recap:
- 向量搜索,也称为语义搜索,可以在不需要精确文本匹配的情况下识别相关对象,允许用户基于语义含义而不是精确关键字进行搜索。
- Vector search, also called semantic search, can identify related objects without requiring exact text matches, allowing users to search based on semantic meaning rather than exact keywords.
- 它使用机器学习模型为所有数据对象和查询生成向量嵌入,并进行数学计算以确定相似性。
- It uses machine learning models to generate vector embeddings for all data objects and the query, and doing math calculations to determine similarity.
- 向量嵌入捕获数据的含义和上下文。
- Vector embeddings capture the meaning and context of data.
- 向量数据库通过ANN算法提供对查询的超快响应。
- Vector databases offer super fast responses to queries thanks to ANN algorithms.
- ANN算法以少量准确性换取巨大的速度提升。
- ANN algorithms trade a small amount of accuracy for huge gains in speed.
- 不同类型的向量搜索包括混合搜索或多模态搜索(用于图像、音频或视频)。
- Different types of vector search include hybrid search or multimodal search for images, audio, or video.
- 向量搜索的用例包括检索增强生成(RAG)、推荐系统或搜索系统。
- Use cases of vector search include Retrieval Augmented Generation (RAG), recommendation systems, or search systems.
准备开始构建了吗?| Ready to start building?
查看快速入门教程,或使用Weaviate Cloud (WCD)的免费试用版构建令人惊叹的应用。
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).