生产就绪的 RAG 应用程序的 12 种调优策略指南
A comprehensive guide on tuning strategies for production-ready RAG applications, covering both ingestion and inferencing stages
A Guide on 12 Tuning Strategies for Production-Ready RAG Applications
生产就绪的 RAG 应用程序的 12 种调优策略指南
Tuning Strategies for Retrieval-Augmented Generation Applications 检索增强生成应用程序的调优策略
Data Science is an experimental science. It starts with the "No Free Lunch Theorem," which states that there is no one-size-fits-all algorithm that works best for every problem. And it results in data scientists using experiment tracking systems to help them tune the hyperparameters of their Machine Learning (ML) projects to achieve the best performance. 数据科学是一门实验科学。它始于"没有免费午餐定理",该定理指出,没有一种万能算法能够最好地解决所有问题。这导致数据科学家使用实验跟踪系统来帮助他们调整机器学习(ML)项目的超参数以实现最佳性能.
This article looks at a Retrieval-Augmented Generation (RAG) pipeline through the eyes of a data scientist. It discusses potential "hyperparameters" you can experiment with to improve your RAG pipeline's performance. Similar to experimentation in Deep Learning, where, e.g., data augmentation techniques are not a hyperparameter but a knob you can tune and experiment with, this article will also cover different strategies you can apply, which are not per se hyperparameters. 本文从数据科学家的角度审视检索增强生成(RAG)管道。它讨论了您可以试验的潜在"超参数"以提高RAG管道的性能。类似于深度学习中的实验,在深度学习中,例如,数据增强技术不是超参数,而是您可以调整和试验的旋钮,本文还将涵盖您可以应用的不同策略,这些策略本身并不是超参数。
Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation 检索增强生成(RAG):从理论到LangChain实现
This article covers the following "hyperparameters" sorted by their relevant stage. In the ingestion stage of a RAG pipeline, you can achieve performance improvements by: 本文涵盖了按相关阶段排序的以下"超参数"。在RAG管道的摄取阶段中,您可以通过以下方式实现性能改进:
- Data cleaning
- Chunking
- Embedding models
- Metadata
- Multi-indexing
- Indexing algorithms
- 数据清理
- 分块
- 嵌入模型
- 元数据
- 多索引
- 索引算法
And in the inferencing stage (retrieval and generation), you can tune: 在推理阶段(检索和生成)中,您可以调整:
- Query transformations
- Retrieval parameters
- Advanced retrieval strategies
- Re-ranking models
- LLMs
- Prompt engineering
- 查询转换
- 检索参数
- 高级检索策略
- 重排序模型
- 大语言模型
- 提示工程
Note that this article covers text-use cases of RAG. For multimodal RAG applications, different considerations may apply. 请注意,本文涵盖了RAG的文本使用案例。对于多模态RAG应用程序,可能需要考虑不同的因素。
Ingestion Stage
摄取阶段
The ingestion stage is a preparation step for building a RAG pipeline, similar to the data cleaning and preprocessing steps in an ML pipeline. Usually, the ingestion stage consists of the following steps: 摄取阶段是构建RAG管道的准备步骤,类似于ML管道中的数据清理和预处理步骤。通常,摄取阶段包括以下步骤:
- Collect data
- Chunk data
- Generate vector embeddings of chunks
- Store vector embeddings and chunks in a vector database
- 收集数据
- 分块数据
- 生成块的向量嵌入
- 在向量数据库中存储向量嵌入和块
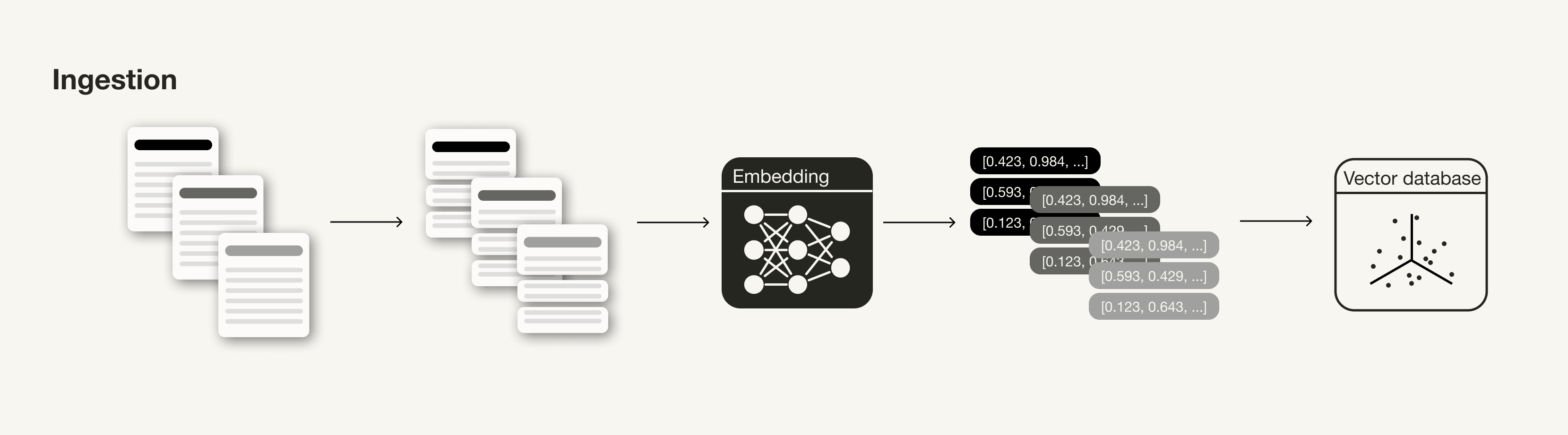
Ingestion stage of a RAG pipeline RAG管道的摄取阶段
This section discusses impactful techniques and hyperparameters that you can apply and tune to improve the relevance of the retrieved contexts in the inferencing stage. 本节讨论有影响力的技巧和超参数,您可以应用和调整这些技巧和超参数以提高推理阶段检索上下文的相关性。
Data cleaning
数据清理
Like any Data Science pipeline, the quality of your data heavily impacts the outcome in your RAG pipeline [8, 9]. Before moving on to any of the following steps, ensure that your data meets the following criteria: 与任何数据科学管道一样,数据的质量会严重影响RAG管道的结果[8, 9]。在进行以下任何步骤之前,请确保您的数据满足以下标准:
- Clean: Apply at least some basic data cleaning techniques commonly used in Natural Language Processing, such as making sure all special characters are encoded correctly.
- Correct: Make sure your information is consistent and factually accurate to avoid conflicting information confusing your LLM.
- 清理:应用至少一些自然语言处理中常用的基数据清理技术,例如确保所有特殊字符都正确编码。
- 正确:确保您的信息一致且事实准确,以避免冲突信息混淆您的LLM。
Chunking
分块
Chunking your documents is an essential preparation step for your external knowledge source in a RAG pipeline that can impact the performance [1, 8, 9]. It is a technique to generate logically coherent snippets of information, usually by breaking up long documents into smaller sections (but it can also combine smaller snippets into coherent paragraphs). 在RAG管道中,对文档进行分块是外部知识源的重要准备步骤,可能会影响性能[1, 8, 9]。这是一种生成逻辑连贯信息片段的技术,通常通过将长文档分解为较小的部分来实现(但它也可以将较小的片段组合成连贯的段落)。
One consideration you need to make is the choice of the chunking technique. For example, in LangChain, different text splitters split up documents by different logics, such as by characters, tokens, etc. This depends on the type of data you have. For example, you will need to use different chunking techniques if your input data is code vs. if it is a Markdown file. 您需要考虑的一个因素是分块技术的选择。例如,在LangChain中,不同的文本分割器按不同的逻辑分割文档,例如按字符、标记等。这取决于您拥有的数据类型。例如,如果您的输入数据是代码而不是Markdown文件,您将需要使用不同的分块技术。
The ideal length of your chunk (chunk_size) depends on your use case: If your use case is question answering, you may need shorter specific chunks, but if your use case is summarization, you may need longer chunks. Additionally, if a chunk is too short, it might not contain enough context. On the other hand, if a chunk is too long, it might contain too much irrelevant information.
理想的**块长度(chunk_size)**取决于您的用例:如果您的用例是问答,您可能需要较短的特定块,但如果您的用例是摘要,您可能需要较长的块。此外,如果块太短,它可能不包含足够的上下文。另一方面,如果块太长,它可能包含太多无关信息。
Additionally, you will need to think about a "rolling window" between chunks (overlap) to introduce some additional context.
此外,您需要考虑块之间的**"滚动窗口"(overlap)**以引入一些额外的上下文。
Embedding models
嵌入模型
Embedding models are at the core of your retrieval. The quality of your embeddings heavily impacts your retrieval results [1, 4]. Usually, the higher the dimensionality of the generated embeddings, the higher the precision of your embeddings. 嵌入模型是检索的核心。嵌入的质量会严重影响您的检索结果[1, 4]。通常,生成的嵌入的维度越高,嵌入的精度就越高。
For an idea of what alternative embedding models are available, you can look at the Massive Text Embedding Benchmark (MTEB) Leaderboard, which covers 164 text embedding models (at the time of this writing). 要了解有哪些替代嵌入模型可用,您可以查看大规模文本嵌入基准(MTEB)排行榜,其中涵盖了164个文本嵌入模型(在撰写本文时)。
MTEB Leaderboard – a Hugging Face Space by mteb MTEB排行榜 – 由mteb提供的Hugging Face空间
While you can use general-purpose embedding models out-of-the-box, it may make sense to fine-tune your embedding model to your specific use case in some cases to avoid out-of-domain issues later on [9]. According to experiments conducted by LlamaIndex, fine-tuning your embedding model can lead to a 5–10% performance increase in retrieval evaluation metrics [2]. 虽然您可以开箱即用地使用通用嵌入模型,但在某些情况下,为了您的特定用例微调您的嵌入模型可能很有意义,以避免以后出现域外问题[9]。根据LlamaIndex进行的实验,微调您的嵌入模型可以带来检索评估指标5-10%的性能提升[2]。
Note that you cannot fine-tune all embedding models (e.g., OpenAI's text-ebmedding-ada-002 can't be fine-tuned at the moment).
请注意,您不能微调所有嵌入模型(例如,OpenAI的text-embedding-ada-002目前无法微调)。
Metadata
元数据
When you store vector embeddings in a vector database, some vector databases let you store them together with metadata (or data that is not vectorized). Annotating vector embeddings with metadata can be helpful for additional post-processing of the search results, such as metadata filtering [1, 3, 8, 9]. For example, you could add metadata, such as the date, chapter, or subchapter reference. 当您在向量数据库中存储向量嵌入时,一些向量数据库允许您将它们与元数据(或未向量化的数据)一起存储。用元数据注释向量嵌入有助于搜索结果的额外后处理,例如元数据过滤[1, 3, 8, 9]。例如,您可以添加元数据,如日期、章节或子章节引用。
Multi-indexing
多索引
If the metadata is not sufficient enough to provide additional information to separate different types of context logically, you may want to experiment with multiple indexes [1, 9]. For example, you can use different indexes for different types of documents. Note that you will have to incorporate some index routing at retrieval time [1, 9]. If you are interested in a deeper dive into metadata and separate collections, you might want to learn more about the concept of native multi-tenancy. 如果元数据不足以提供额外信息来逻辑上分离不同类型的上下文,您可能想要试验多个索引[1, 9]。例如,您可以为不同类型的文档使用不同的索引。请注意,您必须在检索时合并一些索引路由[1, 9]。如果您想深入了解元数据和独立集合,您可能想了解更多关于原生多租户概念的信息。
Indexing algorithms
索引算法
To enable lightning-fast similarity search at scale, vector databases and vector indexing libraries use an Approximate Nearest Neighbor (ANN) search instead of a k-nearest neighbor (kNN) search. As the name suggests, ANN algorithms approximate the nearest neighbors and thus can be less precise than a kNN algorithm. 为了实现大规模的闪电般快速相似性搜索,向量数据库和向量索引库使用近似最近邻(ANN)搜索而不是k最近邻(kNN)搜索。顾名思义,ANN算法近似最近邻,因此可能不如kNN算法精确。
There are different ANN algorithms you could experiment with, such as Facebook Faiss (clustering), Spotify Annoy (trees), Google ScaNN (vector compression), and HNSWLIB (proximity graphs). Also, many of these ANN algorithms have some parameters you could tune, such as ef, efConstruction, and maxConnections for HNSW [1].
您可以试验不同的ANN算法,例如Facebook Faiss(聚类)、Spotify Annoy(树)、Google ScaNN(向量压缩)和HNSWLIB(邻近图)。此外,许多这些ANN算法都有一些您可以调整的参数,例如HNSW的ef、efConstruction和maxConnections[1]。
Additionally, you can enable vector compression for these indexing algorithms. Analogous to ANN algorithms, you will lose some precision with vector compression. However, depending on the choice of the vector compression algorithm and its tuning, you can optimize this as well. 此外,您可以为这些索引算法启用向量压缩。类似于ANN算法,您会在向量压缩中失去一些精度。但是,根据向量压缩算法的选择和调整,您也可以优化这一点。
However, in practice, these parameters are already tuned by research teams of vector databases and vector indexing libraries during benchmarking experiments and not by developers of RAG systems. However, if you want to experiment with these parameters to squeeze out the last bits of performance, I recommend this article as a starting point:
An Overview on RAG Evaluation | Weaviate – vector database 然而,在实践中,这些参数已经在基准测试实验期间由向量数据库和向量索引库的研究团队进行了调整,而不是由RAG系统的开发人员调整。但是,如果您想试验这些参数以榨取最后一点性能,我推荐这篇文章作为起点: RAG评估概述 | Weaviate – 向量数据库
Inferencing Stage (Retrieval & Generation)
推理阶段(检索与生成)
The main components of the RAG pipeline are the retrieval and the generative components. This section mainly discusses strategies to improve the retrieval (Query transformations, retrieval parameters, advanced retrieval strategies, and re-ranking models) as this is the more impactful component of the two. But it also briefly touches on some strategies to improve the generation (LLM and prompt engineering). RAG管道的主要组件是检索组件和生成组件。本节主要讨论改进检索的策略(查询转换、检索参数、高级检索策略和重排序模型),因为这是两个组件中影响更大的组件。但它也简要涉及了一些改进生成的策略(大语言模型和提示工程)。
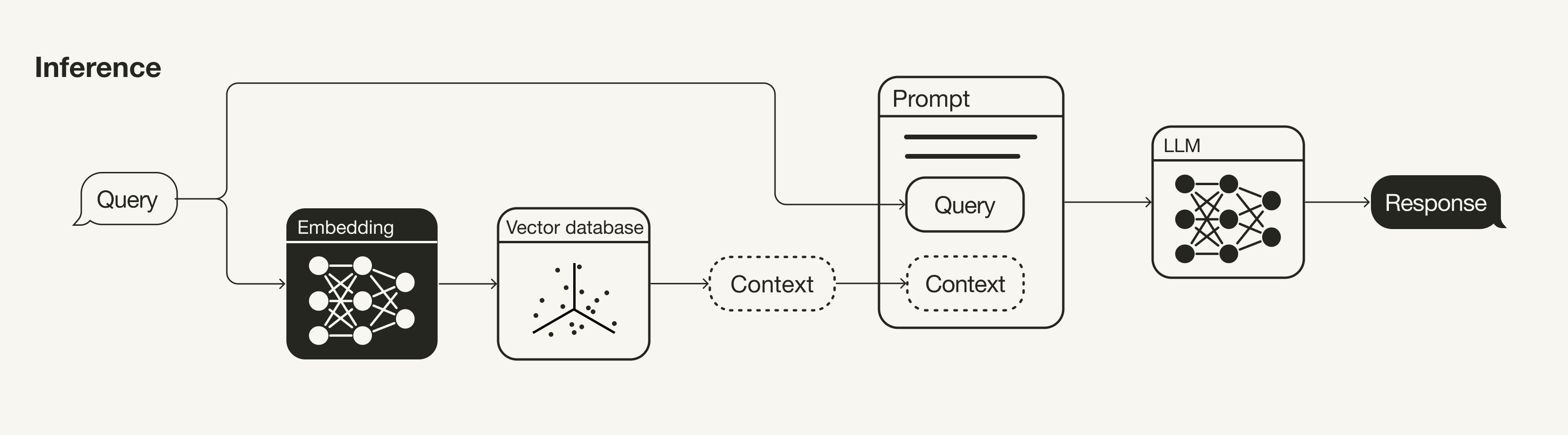
Inference stage of a RAG pipeline RAG管道的推理阶段
Query transformations
查询转换
Since the search query to retrieve additional context in a RAG pipeline is also embedded into the vector space, its phrasing can also impact the search results. Thus, if your search query doesn't result in satisfactory search results, you can experiment with various query transformation techniques [5, 8, 9], such as:
- Rephrasing: Use an LLM to rephrase the query and try again.
- Hypothetical Document Embeddings (HyDE): Use an LLM to generate a hypothetical response to the search query and use both for retrieval.
- Sub-queries: Break down longer queries into multiple shorter queries.
- 重新措辞:使用LLM重新措辞查询并重试。
- 假设文档嵌入(HyDE):使用LLM生成对搜索查询的假设响应,并将两者都用于检索。
- 子查询:将较长的查询分解为多个较短的查询。
Retrieval parameters
检索参数
The retrieval is an essential component of the RAG pipeline. The first consideration is whether semantic search will be sufficient for your use case or if you want to experiment with hybrid search. 检索是RAG管道的重要组件。第一个考虑因素是语义搜索是否足以满足您的用例,或者您是否想试验混合搜索。
In the latter case, you need to experiment with weighting the aggregation of sparse and dense retrieval methods in hybrid search [1, 4, 9]. Thus, tuning the parameter alpha, which controls the weighting between semantic (alpha = 1) and keyword-based search (alpha = 0), will become necessary.
在后一种情况下,您需要试验混合搜索中稀疏和密集检索方法聚合的加权[1, 4, 9]。因此,调整参数**alpha,它控制语义搜索(alpha = 1)和基于关键字的搜索(alpha = 0)之间的加权**将变得必要。
Improving Retrieval Performance in RAG Pipelines with Hybrid Search 使用混合搜索提高RAG管道中的检索性能
Also, the number of search results to retrieve will play an essential role. The number of retrieved contexts will impact the length of the used context window (see Prompt Engineering). Also, if you are using a re-ranking model, you need to consider how many contexts to input to the model (see Re-ranking models). 此外,要检索的搜索结果数量将发挥重要作用。检索到的上下文数量将影响使用的上下文窗口的长度(参见提示工程)。此外,如果您正在使用重排序模型,您需要考虑向模型输入多少上下文(参见重排序模型)。
Note, while the used similarity measure for semantic search is a parameter you can change, you should not experiment with it but instead set it according to the used embedding model (e.g., [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) supports cosine similarity or [multi-qa-MiniLM-l6-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1#technical-details) supports cosine similarity, dot product, and Euclidean distance).
请注意,虽然用于语义搜索的相似性度量是您可以更改的参数,但您不应对其进行试验,而应根据使用的嵌入模型进行设置(例如,[text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings)支持余弦相似性,或[multi-qa-MiniLM-l6-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1#technical-details)支持余弦相似性、点积和欧几里得距离)。
Advanced retrieval strategies
高级检索策略
This section could technically be its own article. For this overview, we will keep this as concise as possible. For an in-depth explanation of the following techniques, I recommend this DeepLearning.AI course:
Building and Evaluating Advanced RAG Applications 从技术上讲,本节可以成为一篇独立的文章。为了这个概述,我们将尽可能简洁。对于以下技术的深入解释,我推荐这个DeepLearning.AI课程: 构建和评估高级RAG应用程序
The underlying idea of this section is that the chunks for retrieval shouldn't necessarily be the same chunks used for the generation. Ideally, you would embed smaller chunks for retrieval (see Chunking) but retrieve bigger contexts. [7] 本节的基本思想是,用于检索的块不一定与用于生成的块相同。理想情况下,您会为检索嵌入较小的块(参见分块),但检索更大的上下文。[7]
- Sentence-window retrieval: Do not just retrieve the relevant sentence, but the window of appropriate sentences before and after the retrieved one.
- Auto-merging retrieval: The documents are organized in a tree-like structure. At query time, separate but related, smaller chunks can be consolidated into a larger context.
- 句子窗口检索:不要只检索相关句子,而是检索检索句子前后适当句子的窗口。
- 自动合并检索:文档以树状结构组织。在查询时,可以将独立但相关的较小块合并为更大的上下文。
Re-ranking models
重排序模型
While semantic search retrieves context based on its semantic similarity to the search query, "most similar" doesn't necessarily mean "most relevant". Re-ranking models, such as Cohere's Rerank model, can help eliminate irrelevant search results by computing a score for the relevance of the query for each retrieved context [1, 9]. 虽然语义搜索根据其与搜索查询的语义相似性检索上下文,但"最相似"不一定意味着"最相关"。重排序模型,例如Cohere的Rerank模型,可以通过为每个检索到的上下文计算查询相关性得分来帮助消除不相关的搜索结果[1, 9]。
"most similar" doesn't necessarily mean "most relevant" "最相似"不一定意味着"最相关"
If you are using a re-ranker model, you may need to re-tune the number of search results for the input of the re-ranker and how many of the reranked results you want to feed into the LLM. 如果您正在使用重排序模型,您可能需要重新调整搜索结果的数量作为重排序器的输入,以及您想要将多少重排序结果输入到LLM中。
As with the embedding models, you may want to experiment with fine-tuning the re-ranker to your specific use case. 与嵌入模型一样,您可能想要为您的特定用例微调重排序器。
LLMs
大语言模型
The LLM is the core component for generating the response. Similarly to the embedding models, there is a wide range of LLMs you can choose from depending on your requirements, such as open vs. proprietary models, inferencing costs, context length, etc. [1] LLM是生成响应的核心组件。与嵌入模型类似,您可以根据需求选择各种LLM,例如开源模型与专有模型、推理成本、上下文长度等。[1]
As with the embedding models or re-ranking models, you may want to experiment with fine-tuning the LLM to your specific use case to incorporate specific wording or tone of voice. 与嵌入模型或重排序模型一样,您可能想要为您的特定用例微调LLM以融入特定的措辞或语调。
Prompt engineering
提示工程
How you phrase or engineer your prompt will significantly impact the LLM's completion [1, 8, 9]. 您如何措辞或**设计提示**将显著影响LLM的完成[1, 8, 9].
Please base your answer only on the search results and nothing else!非常重要!您的答案必须基于提供的搜索结果。
请解释为什么您的答案基于搜索结果!Additionally, using few-shot examples in your prompt can improve the quality of the completions. 此外,在提示中使用少样本示例可以提高完成的质量。
As mentioned in Retrieval parameters, the number of contexts fed into the prompt is a parameter you should experiment with [1]. While the performance of your RAG pipeline can improve with increasing relevant context, you can also run into a "Lost in the Middle" [6] effect where relevant context is not recognized as such by the LLM if it is placed in the middle of many contexts. 如检索参数中所述,输入提示的上下文数量是您应该试验的参数[1]。虽然随着相关上下文的增加,RAG管道的性能可以提高,但您也可能遇到"迷失在中间"[6]效应,即如果相关上下文放置在许多上下文的中间,LLM不会将其识别为相关上下文。
Summary
总结
As more and more developers gain experience with prototyping RAG pipelines, it becomes more important to discuss strategies to bring RAG pipelines to production-ready performances. This article discussed different "hyperparameters" and other knobs you can tune in a RAG pipeline according to the relevant stages: 随着越来越多的开发人员在RAG管道原型设计方面获得经验,讨论将RAG管道提升到生产就绪性能的策略变得越来越重要。本文讨论了可以根据相关阶段在RAG管道中调整的不同"超参数"和其他旋钮:
This article covered the following strategies in the ingestion stage: 本文涵盖了摄取阶段的以下策略:
- Data cleaning: Ensure data is clean and correct.
- Chunking: Choice of chunking technique, chunk size (
chunk_size) and chunk overlap (overlap). - Embedding models: Choice of the embedding model, incl. dimensionality, and whether to fine-tune it.
- Metadata: Whether to use metadata and choice of metadata.
- Multi-indexing: Decide whether to use multiple indexes for different data collections.
- Indexing algorithms: Choice and tuning of ANN and vector compression algorithms can be tuned but are usually not tuned by practitioners.
- 数据清理:确保数据干净正确。
- 分块:分块技术的选择、块大小(
chunk_size)和块重叠(overlap)。 - 嵌入模型:嵌入模型的选择,包括维度,以及是否微调。
- 元数据:是否使用元数据和元数据的选择。
- 多索引:决定是否为不同的数据集合使用多个索引。
- 索引算法:ANN和向量压缩算法的选择和调整可以调整,但通常不被从业者调整。
And the following strategies in the inferencing stage (retrieval and generation): 以及推理阶段(检索和生成)的以下策略:
- Query transformations: Experiment with rephrasing, HyDE, or sub-queries.
- Retrieval parameters: Choice of search technique (
alphaif you have hybrid search enabled) and the number of retrieved search results. - Advanced retrieval strategies: Whether to use advanced retrieval strategies, such as sentence-window or auto-merging retrieval.
- Re-ranking models: Whether to use a re-ranking model, choice of re-ranking model, number of search results to input into the re-ranking model, and whether to fine-tune the re-ranking model.
- LLMs: Choice of LLM and whether to fine-tune it.
- Prompt engineering: Experiment with different phrasing and few-shot examples.
- 查询转换:试验重新措辞、HyDE或子查询。
- 检索参数:搜索技术的选择(如果启用了混合搜索则为
alpha)和检索到的搜索结果数量。 - 高级检索策略:是否使用高级检索策略,如句子窗口或自动合并检索。
- 重排序模型:是否使用重排序模型、重排序模型的选择、输入重排序模型的搜索结果数量,以及是否微调重排序模型。
- 大语言模型:LLM的选择以及是否微调它。
- 提示工程:试验不同的措辞和少样本示例。